

Couchbase x Medblocks - Building a NoSQL FHIR Server
We walk you through building a FHIR server on top of Couchbase's NoSQL database, covering challenges, technical decisions, architecture, and local setup.
October 28, 2022
This article is supplementary to the above video that provides a brief overview of the steps and methods involved.
Migrating data systems is a frequent problem when dealing with legacy systems in industries such as healthcare.
A very robust way to tackle such a problem is using ETLs. ETL is an abbreviation that involves three words that indicate three phases of data transformation.
Extract involves getting data from legacy applications for transformation. This tutorial uses the extract phase as a continuous service that reacts to live database changes in the legacy application as opposed to a one-time load and transform. If your need is just one time then only some parts of this tutorial will fit you.
Using a message broker in the chain helps batch data and maintain versions and idempotency. A message broker such as ZeroMQ, Kafka, or RabbitMQ is ideal. This tutorial uses Apache NIFI on Apache Kafka as a message broker in the extract phase. We prefer Kafka for its scale-out properties, ability to persist and replay messages, and the rich community of connector plugins available.
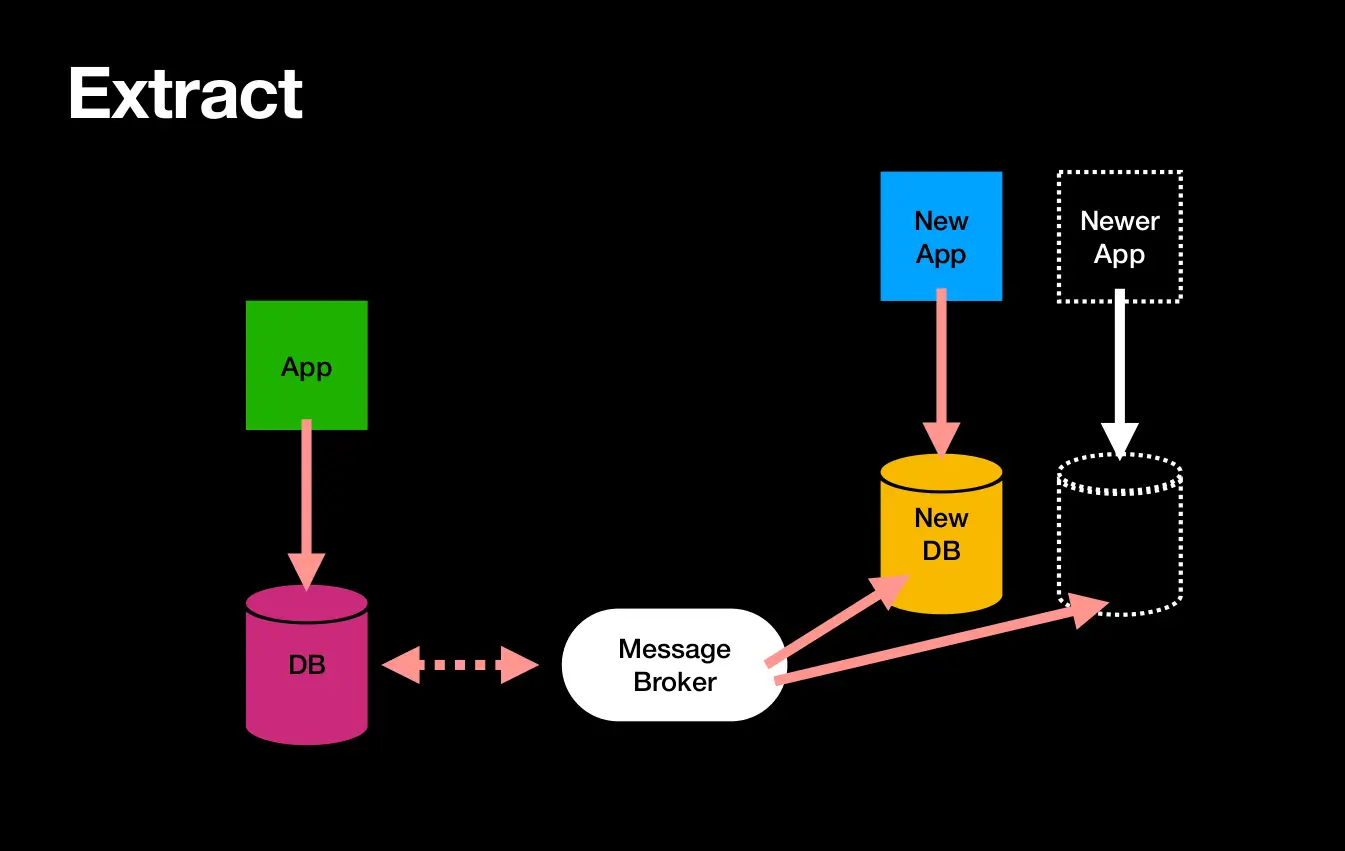
Apache Debezium is an open-source platform that streams change happening in the database. It supports all commonly used databases such as Postgres, MySQL, MongoDB, Cassandra, etc.,
The tool used for the ETL pipeline is Apache Nifi, an open-source tool that manages all workflows.
Apache Nifi listens to the Kafka topic that Debezium pushes to and performs a set of actions to transform the data into the FHIR format. Nifi can easily plugin into any programming ecosystem and run scripts as basic commands from the browser itself. In this instance, we use a singular Python script on Nifi to transform the data.
The Python script outputs a FHIR bundle resource that would later perform a PUT operation to the Nifi pipeline in order to avoid duplication of records on the queue. Here it’s important to derive an idempotent key as the id of the Patient, we just UUIDv5 hash the primary key of the patient.
The load phase is rather simple in our case as it is a simple POST request to the FHIR server with the Bundle of patient records.
The advantage of using systems such as Nifi is the ability to maintain sync between the systems being migrated. Apart from the brief delay in transformation on the pipeline data is instantly updated and two separate systems - legacy database and FHIR store stay in sync.
This helps us at Medblocks maintain different stores for business logic and clinical workflows.
We walk you through building a FHIR server on top of Couchbase's NoSQL database, covering challenges, technical decisions, architecture, and local setup.
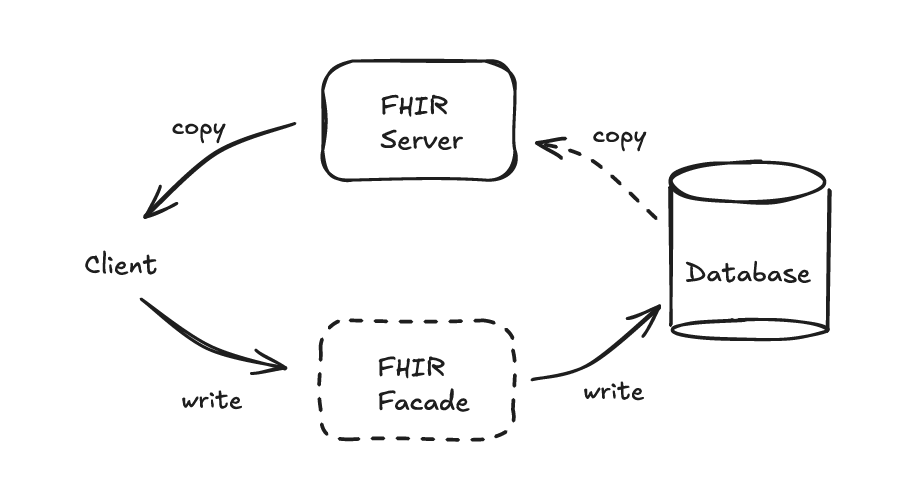
Explore three approaches to building RESTful FHIR servers: Facade, Synchronization, & Hybrid. Understand where REST APIs, Documents, and Messaging fit in FHIR.
Learn to build a Python FHIR Facade using FastAPI and PostgreSQL to expose legacy EHR data as FHIR APIs supporting read search operations and interoperability
No comments yet. Be the first to comment!
