

Why We're Reinventing the EHR
Traditional healthcare software development has significant drawbacks. A platform with standardized features and extensible features might be the right answer.
April 17, 2025
Over the past year, we have been working hard on a new engine and specification that maps two major open health standards - openEHR and FHIR. Today, we’re open-sourcing all of our work under the Apache 2.0 license.
There’s been a lot of questions around how (or whether) openEHR and FHIR should work together. Some look at these as competing standards with different core philosophies suitable for use at different scales, while others pragmatically say they are to be used together, because they solve different problems.
If you like spending your day watching people debate, this discourse post is for you.
Overall, looking at the bigger picture, there’s been an undeniable shift in the mindset of people in moving from traditional single-vendor EMR systems to Health Data Platforms that separates data from the application.
There’s been a mushrooming of “headless EHRs” and “standards-first” development platforms for healthcare on both the FHIR (Health Samurai, Medplum) and the openEHR (Better, CODE24, Tietoevery, vitagroup) camps.
The FHIR philosophy is that the developer experience that comes first, and data modeling happens after two or more parties agree on the use case. These are represented as Implementation Guides (IGs), and form the basis of interoperability.
On the openEHR side, the maximal clinical models (archetypes) are not dependent on a particular use case. These archetypes are then constrained and used in different settings. The basis of interoperability is archetype reuse. While this works out well in theory, openEHR is just starting to gain more traction, and the developer experience and open-source tools have a lot to be desired.
Regardless of which standard is used for the health data platform (hey, sometimes, we use both openEHR and FHIR), the fact remains:
openEHR happens to be a popular choice if you want a longitudinal health record that spans the lifespan of the patient. Especially, if you don’t want to model a lot of clinical data yourself and just use the available archetypes on the CKM.
FHIR is the preferred standard that most governments use to enforce interoperability between systems (thank you USA?. While this maybe changing, it is safe to say FHIR-based interoperability whether through messaging, or SMART, FHIR is here to stay for the next two decades, at least.
So it’s usually “openEHR for persistence, FHIR for transport” when you see people talking about the two standards.
However, the data in openEHR needs to be mapped to FHIR, and vice versa. Based on these requirements, 3 major patterns have emerged in how people bridge openEHR and FHIR,
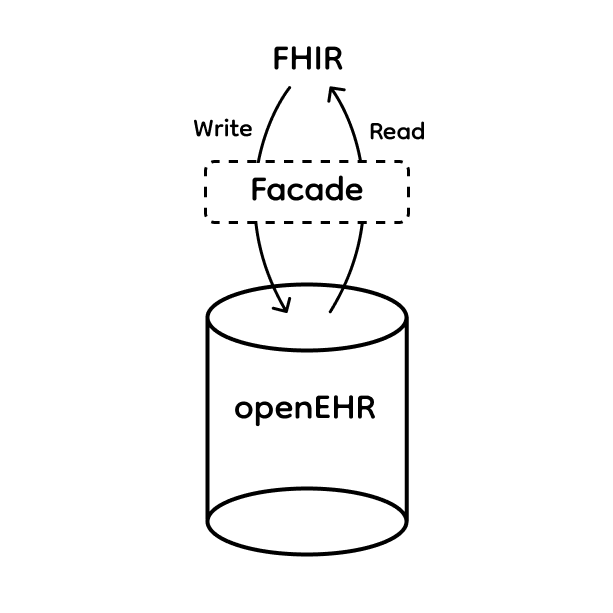 All FHIR API requests are translated to openEHR API calls. This approach is expensive to implement as it requires covering all types of FHIR API requests.
All FHIR API requests are translated to openEHR API calls. This approach is expensive to implement as it requires covering all types of FHIR API requests.
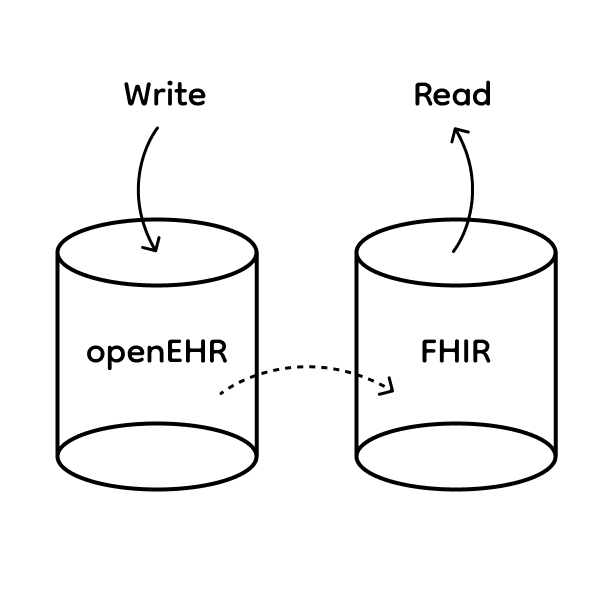 The openEHR data is copied to a FHIR server that implements all APIs. This provides read-only access to FHIR - particularly useful if you want to run read-only SMART on FHIR apps.
The openEHR data is copied to a FHIR server that implements all APIs. This provides read-only access to FHIR - particularly useful if you want to run read-only SMART on FHIR apps.
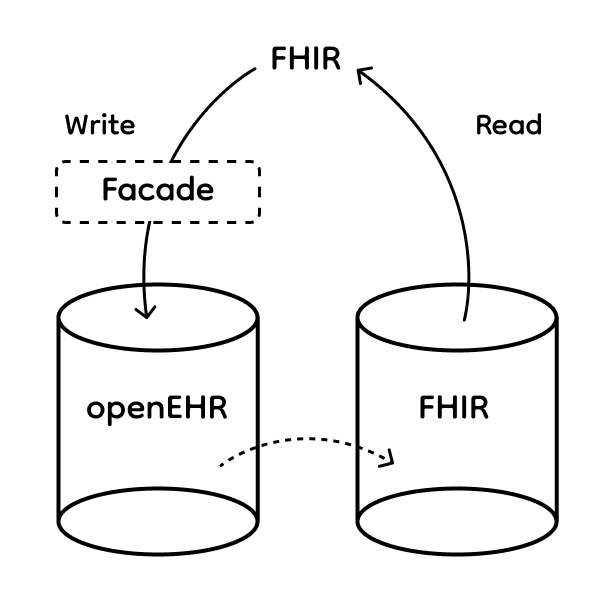 FHIR writes are handled through a facade, while reads (which are the more complex part) are routed to the synchronized FHIR server.
FHIR writes are handled through a facade, while reads (which are the more complex part) are routed to the synchronized FHIR server.
If you can convert openEHR compositions reliably to FHIR Bundles, and back, you can achieve all of the above patterns.
Better set out to solve the problem of mapping openEHR compositions to FHIR Bundles when they developed FHIRConnect. They came out with an open specification (which is now archived, I’ll explain why later) that maps bi-directionally from openEHR compositions to FHIR bundles if given a few declarative YAML files.
Better probably implemented a version of the spec into an engine, but it was not widely used in production, and there was no open-source implementation of this engine available. There was no real “battle-tested” open-source mapping files that were available either.
Around this same time, HiGHmed had contracted Medblocks to rework their FHIR Bridge project and make the mappings between FHIR and openEHR more “declarative”, reusable and easier to maintain - the credit goes to Severin Kohler for the idea. A lot of this effort was under the leadership of Stefan Becker and Dirk Rossbach
We noticed Gasper Andrejc, then a contractor at Fire.ly announce that he had an exciting new engine that implemented the FHIRConnect spec called openFHIR.
The work that Gasper had already put into the openFHIR engine was exciting to us. We knew what we’d build for HiGHmed had a high chance of resembling this. So we had a choice - should we build our own FHIRConnect implementation from scratch or, build on the work that’s already done.
In October 2024, Medblocks formally acquired openFHIR from Gasper Andrajc.
There was still a lot of work to be done, because FHIRConnect as a spec, and openFHIR had never undergone rigorous testing and usage in the field. We had to implement FHIR to openEHR mappings for all of the MII Core Dataset.
This was no easy task.
When we started implementing the MII Core Dataset mappings, we ran into multiple issues when using Better’s version of FHIRConnect. The original FHIRConnect spec had a great vision - create reusable mappings that, like archetypes, could be adapted for different scenarios. These “maximal mappings” would, in theory, work across many use cases.
But reality hit hard. We found key gaps in the spec when mapping complex clinical data:
Severin Kohler led this redesign effort, creating a more flexible approach that works not just for the MII Core Dataset but also for US Core and Indian ABDM profiles.
This led us to split mappings into three distinct layers instead of the previous two we had:
We then asked Better to archive their specification and the latest is now published as the FHIRconnect Specification (v1.0.0).
This is almost an entire rewrite of the FHIRConnect spec, and we are confident in saying that it actually works. For a detailed breakdown of the specs, checkout this 2-hour long podcast episode with Severin.
Enough talk. Ready to try openFHIR?
Let’s get you up and running with a practical example that demonstrates bidirectional mapping between openEHR and FHIR. In this quickstart, we will:
By the end, you’ll have a working instance of openFHIR and a practical understanding of how the mapping engine works. Let’s dive in!
Clone the Repository
git clone https://github.com/medblocks/openFHIR.git
cd openFHIRBuild and Run with Docker Compose
docker-compose build
docker-compose upThis will:
The magic of openFHIR lies in how it translates between two complex health standards using declarative YAML files. The engine works with three types of mapping files:
This layered approach gives us both reusability and flexibility. The complete specification is available in the FHIRConnect documentation.
Let’s examine our blood pressure example (note that we’re showing simplified excerpts - be sure to check the full files for all details):
The model mapping file (blood-pressure.model.yml) defines how the blood pressure archetype maps to a FHIR Observation. Here’s just a small portion of it:
grammar: FHIRConnect/v0.0.1
type: model
metadata:
name: OBSERVATION.blood_pressure.v2
version: 0.0.1a # version of this particular mapping
spec: # schema specific to the FHIRConnect v0.0.1 engine
system: FHIR
version: R4
openEhrConfig:
archetype: openEHR-EHR-OBSERVATION.blood_pressure.v2
fhirConfig:
structureDefinition: http://hl7.org/fhir/StructureDefinition/Observation
# Actual mapping points:
mappings:
- name: "systolic"
with:
fhir: "$resource.component.value"
openehr: "$archetype/data[at0001]/events[at0006]/data[at0003]/items[at0004]"
fhirCondition:
# This condition helps identify the right component in the FHIR resource
targetRoot: "$resource.component"
targetAttribute: "code.coding.code"
operator: "one of"
criteria: "[$loinc.8480-6, $snomed.271649006]"
identifying: trueThis mapping point tells the engine: “Map the systolic blood pressure value between these two paths, and when going from FHIR to openEHR, look for a component with a LOINC code of 8480-6 or a SNOMED code of 271649006.”
The full model mapping file includes many more mapping points for diastolic blood pressure, clinical interpretation, and other elements.
The context mapping file (simple-blood-pressure.context.yml) defines which template and profile we’re using:
grammar: FHIRConnect/v0.0.1
type: context
metadata:
name: "Blood Pressure"
version: 0.0.1a # version of this particular mapping
spec: # schema specific to the FHIRConnect v0.0.1 engine
system: FHIR
version: R4
context:
profile:
url: "Observation"
template:
id: "Blood Pressure"
archetypes:
- "OBSERVATION.blood_pressure.v2"
start: "OBSERVATION.blood_pressure.v2"This file serves as a bridge between the two systems, connecting the openEHR template with the FHIR profile. While this context file is relatively simple, context files for more complex mappings can include additional configuration options.
Now that we understand how the mapping files work, let’s test them with our openFHIR instance. We’ll use the blood pressure example files from the repository located in src/test/resources/blood_pressure/.
etc/openFHIR_oss.postman_collection.jsonbaseurl pointing to your openFHIR instance (e.g., http://localhost:8080)Follow these steps in Postman:
1. Upload OPT Template
Create a new POST request:
{{baseurl}}/optContent-Type: application/xml2. Upload Model Definition
Create a new POST request:
{{baseurl}}/fc/modelContent-Type: text/plain3. Upload Context Definition
Create a new POST request:
{{baseurl}}/fc/contextContent-Type: text/plain4. Convert openEHR to FHIR
Create a new POST request:
{{baseurl}}/openfhir/tofhir?templateId=Blood PressureContent-Type: application/json{
"blood_pressure/blood_pressure/any_event:0/systolic|magnitude": 120.0,
"blood_pressure/blood_pressure/any_event:0/systolic|unit": "mm[Hg]",
"blood_pressure/blood_pressure/any_event:0/diastolic|magnitude": 80.0,
"blood_pressure/blood_pressure/any_event:0/diastolic|unit": "mm[Hg]",
"blood_pressure/blood_pressure/any_event:0/clinical_interpretation": "Normal blood pressure"
}This flat JSON structure represents the openEHR composition. The engine will transform it into a structured FHIR Observation resource.
5. Convert FHIR to openEHR
Create a new POST request:
{{baseurl}}/openfhir/toopenehr?templateId=Blood PressureContent-Type: application/json{
"resourceType": "Bundle",
"entry": [
{
"resource": {
"resourceType": "Observation",
"status": "final",
"code": {
"coding": [
{
"system": "http://loinc.org",
"code": "85354-9",
"display": "Blood pressure panel"
}
]
},
"component": [
{
"code": {
"coding": [
{
"system": "http://loinc.org",
"code": "8480-6",
"display": "Systolic blood pressure"
}
]
},
"valueQuantity": {
"value": 120,
"unit": "mm[Hg]",
"system": "http://unitsofmeasure.org",
"code": "mm[Hg]"
}
},
{
"code": {
"coding": [
{
"system": "http://loinc.org",
"code": "8462-4",
"display": "Diastolic blood pressure"
}
]
},
"valueQuantity": {
"value": 80,
"unit": "mm[Hg]",
"system": "http://unitsofmeasure.org",
"code": "mm[Hg]"
}
}
]
}
}
]
}This structured FHIR Bundle will be transformed back into the flat openEHR structure. The engine handles the bidirectional mapping using the mapping files we uploaded earlier.
For a more detailed walkthrough, you can take a look at this video walkthrough with Gasper.
The FHIRConnect specification supports many advanced features beyond what we’ve shown in this simple example:
These features allow the engine to handle complex clinical data structures while maintaining the semantic meaning across both standards. For a complete understanding of what’s possible, see the FHIRConnect specification.
When we acquired the openFHIR project, making it open source wasn’t just an afterthought - it was fundamental to our vision from day one. Here’s why:
The HiGHmed project initially only required one-way FHIR-to-openEHR mappings. We could have stopped there, but we saw the bigger picture:
We simply couldn’t have achieved this level of functionality within our timeline if we hadn’t planned to open-source the project from the beginning. Knowing the work would benefit everyone aligned all our partners and motivated us to go beyond the minimum requirements.
In the paper, “Converge or Collide”, Racheal, Graham and Guy argued that using the right standard for the right job is essential. However, this new paper makes an even stronger point: without open-source tooling, these standards can’t reach their potential.
The health data standards world faces a critical shortage of open-source tools and contributors compared to other domains. This gap slows adoption and fragments the market with proprietary implementations that don’t interoperate well - defeating the very purpose of standards.
Here’s a table showing the number of contributors and repositories on GitHub for major healthcare data standards (as of January 28, 2025). Data from Kapitan et al
| Period and search term | Contributors | Repositories | |------------------------|------------:|-------------:| | Last three months | | | | “openEHR” | 82 | 49 | | “OMOP” or “OHDSI” | 446 | 221 | | “FHIR” | 1,648 | 756 | | All time | | | | “openEHR” | 429 | 450 | | “OMOP” or “OHDSI” | 1,019 | 1,113 | | “FHIR” | 8,497 | 8,617 |
As this data clearly shows, there simply aren’t enough open-source repositories and contributors to sustain growth right now, especially for standards like openEHR. This is why the “Open-source or Die” principle is so critical - without robust open-source implementations, even the best-designed standards will struggle to achieve widespread adoption and interoperability.
We deliberately chose the Apache 2.0 license for everything - the engine, mappings, and specification. This permissive license means:
Our philosophy is simple: as the health data platform market expands through better open-source tooling, there will be more than enough business for companies like Medblocks. We’re betting on growing the overall pie rather than protecting a small slice.
We believe open standards backed by open-source implementations are the only sustainable path forward.
With openFHIR, we’ve taken a significant step toward solving the practical challenges of using openEHR and FHIR together. This isn’t just theoretical work – although still in alpha, it’s been battle tested against the MII core dataset, KDS FHIR Profiles, some of US Core and Indian ABDM profiles. It’s a solution that:
We invite you to:
While openFHIR and FHIRConnect aren’t perfect, they represents a meaningful advance in how we approach health data interoperability. We’re committed to improving it with the community’s help.
If you’re working on projects involving openEHR, FHIR, or both, we’d love to hear from you.
Traditional healthcare software development has significant drawbacks. A platform with standardized features and extensible features might be the right answer.

While open standards set the rules, open source gets the work done. Discuss choosing tools, handling semantics and making health systems interoperable.

Health IT has various standards, and choosing the right one is often confusing. Understand the differences clearly to select the right standard.
No comments yet. Be the first to comment!
