Learn core FHIR concepts and also how to deploy your own FHIR server.
A single lab-mainframe interface in 1987 could cost about $100,000. HL7 started as a practical fix to this. Many turns later, it gave us FHIR. But how?
Imagine paying $100,000 just to connect one hospital computer to another. This was hospital interoperability in the 1980s, where having N systems meant building N2 bespoke interfaces.
HL7 began as a solution to this problem, looking for a way to make systems speak a common language. Decades later, that journey gave us FHIR. With its small and fast web resources, it has become the API language of modern healthcare. We’ll explore this evolution through the stories of the people that built them.
Part 1: Technology landscape before HL7
In the 1970s, hospitals had mainframe computers for billing and registration. By the end of the decade, departments added their own minicomputers to meet clinical requirements. Each of these systems was their own little island of data. To exchange this information, they needed to build a custom interface between every two systems, and each could cost around $100,000.
The first workaround was human: nurses walked between terminals in order to access complete information about patient care. Later came “front-end networks” where one terminal could connect to multiple backends. It simplified effort, but did not address data transfer between systems.
A nurse at a terminal
Meanwhile outside healthcare,
The ISO OSI model was developed in 1979. It specified seven layers for information exchange between computers, and it gained popularity in the 80s.
Microprocessors were introduced around 1975.
Data integration systems were in their infancy, finance and logistics used ANSI X12, created in 1979.
Academic precursor to HL7: ASTM E1238
While most academics considered standardization “blue collar work”, there were some pioneers. Clem McDonald, from the Indiana University School of Medicine, and Ed Hammond from Duke University first became interested in interface standards by working with computer-based medical records.
Clem’s editorial titled “Grocers, Physicians and Electronic Data Processing”, was rejected 9 times before it was published in 1983. In it, he argued that healthcare should learn from grocery barcodes that were simple, standardized and universal.
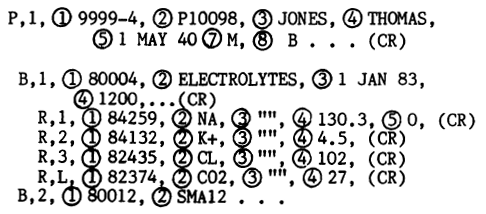
This is what an example laboratory result looked like, where,
the first line starting with P,1,... represents patient details
B,1,... represent the Observation Request, or the test that was ordered
R,1,..., R,1,... and so on represent the Observation Results, or the results of the test
It was comma-heavy, but it worked.
Industry experiments: StatLAN at UCSF
Don Simborg
Donald W Simborg, the CIO at University of California, San Francisco (UCSF) teamed up with Steve Tolchin from John Hopkins Applied Physics Laboratory to develop something to let systems talk machine to machine. They drew inspiration from the air-traffic control systems built by MITRE in the 1950s, connecting multiple computers with a shared protocol.
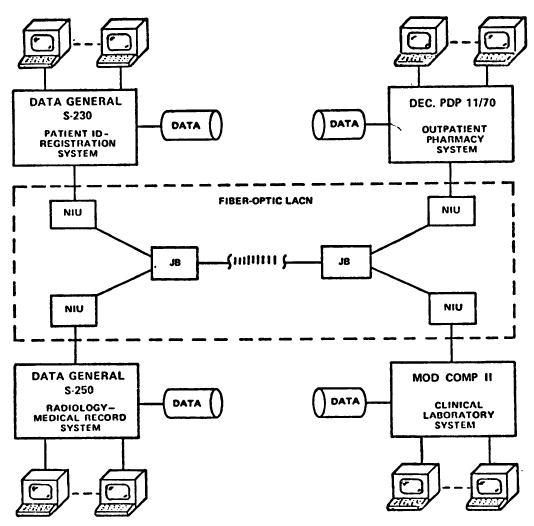
In 1981, the UCSF team ran the first application level (Layer 7) data exchange protocol in healthcare. It shared patient registration, lab, pharmacy and radiology data between 4 systems from different vendors.
UCSF Systems Diagram
This system was later commercialized as StatLAN, and proved that data exchange at level 7 was possible in healthcare.
From proprietary to public
In 1984, Don founded Simborg Systems to bring StatLAN to market, implementing it in 4 hospitals. Soon, they realized that a proprietary protocol wouldn’t survive, vendors needed something open and shared.
So, in 1985 Simborg Systems decided to put StatLAN’s protocol in the public domain, and decided to create a neutral standards body to take it forward. From that decision, HL7 was born.
Part 2: Early HL7 and HL7 v2
On March 29-31, 1987, a group of hospital CIOs, vendors and StatLAN users gathered in Philadelphia. Ed Hammond describes it as the day of the worst electrical storm he’s ever seen.
They had a clear goal: To build an easy to implement standard that was ready for use immediately.
From that meeting, HL7 was born. Founding members included Clem McDonald, Ed Hammond, Don Simbord and Wes Rishel.
Writing HL7 v1 and v2
In a few short months, small working groups were ready with a first version. It included basic transactions for Admissions, Discharges, Transfers (ADT), order entry and queries. V1 proved that interfaces could be repeatable, and not bespoke.
A year later in 1988, HL7 v2 was published. It added billing and lab results, covering critical workflows that hospitals cared about most.
They combined ideas from
StatLAN: Message control and acknowledgements
ASTM E1238: Lab syntax
X12: Batch structures
Marketing, demos and adoption
HL7 didn’t stop at the standard, they marketed it.
A permanent HL7 v2 demonstration at the Coopers & Lybrand Healthcare Technology Center, 1991
At AHA and HIMSS conferences, they held live demonstrations in the 80s versions of today’s Connectathons. This showed vendors and hospitals that information exchange could happen seamlessly.
Because of HL7 v2, interface costs dropped dramatically, from hundreds of thousands to tens of thousands.
Critics were concerned that HL7 was too closely involved with Simborg Systems, and in 1989 Don stepped down as chair. Ed Hammond became the chair, and led HL7 through professionalization, adding formal balloting and eventually ANSI accreditation by 1994.
HL7 v2 adoption
HL7 v2 was simple and fast. Each message was pipe-delimited, every position had a fixed meaning. But that simplicity had its cost.
Sample HL7 v2 message
Hospitals and vendors could add custom Z-segments which were new fields not defined in the official specification. Soon, each HL7 v2 message looked a little different.
If you’ve seen one implementation of HL7 v2, you’ve seen exactly one implementation of HL7 v2.
Still, v2’s success was undeniable. It powered hospital interoperability across the world with its fast, cheap and flexible messaging system.
Part 3: HL7 goes model-first with v3
Cross domain inconsistencies were a major problem with HL7 v2. To fix this, they decided to adopt a shared information model that serves as a single source of truth for all messages
The origins of the RIM
The idea of the shared information model wasn’t new.
IEEE MEDIX proposed a ‘shared universe of discourse’ in 1986. The idea was to model first, then derive messaging from it.
The Joint Working Group - Common Data Model (JWG-CDM) chaired by Woody Beeler had participation from several standards organizations towards this goal.
The MEDIX “shared universe of discourse”
HL7 adopted and built on these ideas. In 1990, the Quality Assurance/Data Modelling (QADM) committee led by Mead Walker outlined a model-first approach. The resulting artifact was the Reference Information Model (RIM).
Building the model
In 1996, Abdul-Malik Shakir volunteered to compile the first RIM. He put together inputs from existing data models from MEDIX, vendors and insurance companies.
Abdul-Malik Shakir
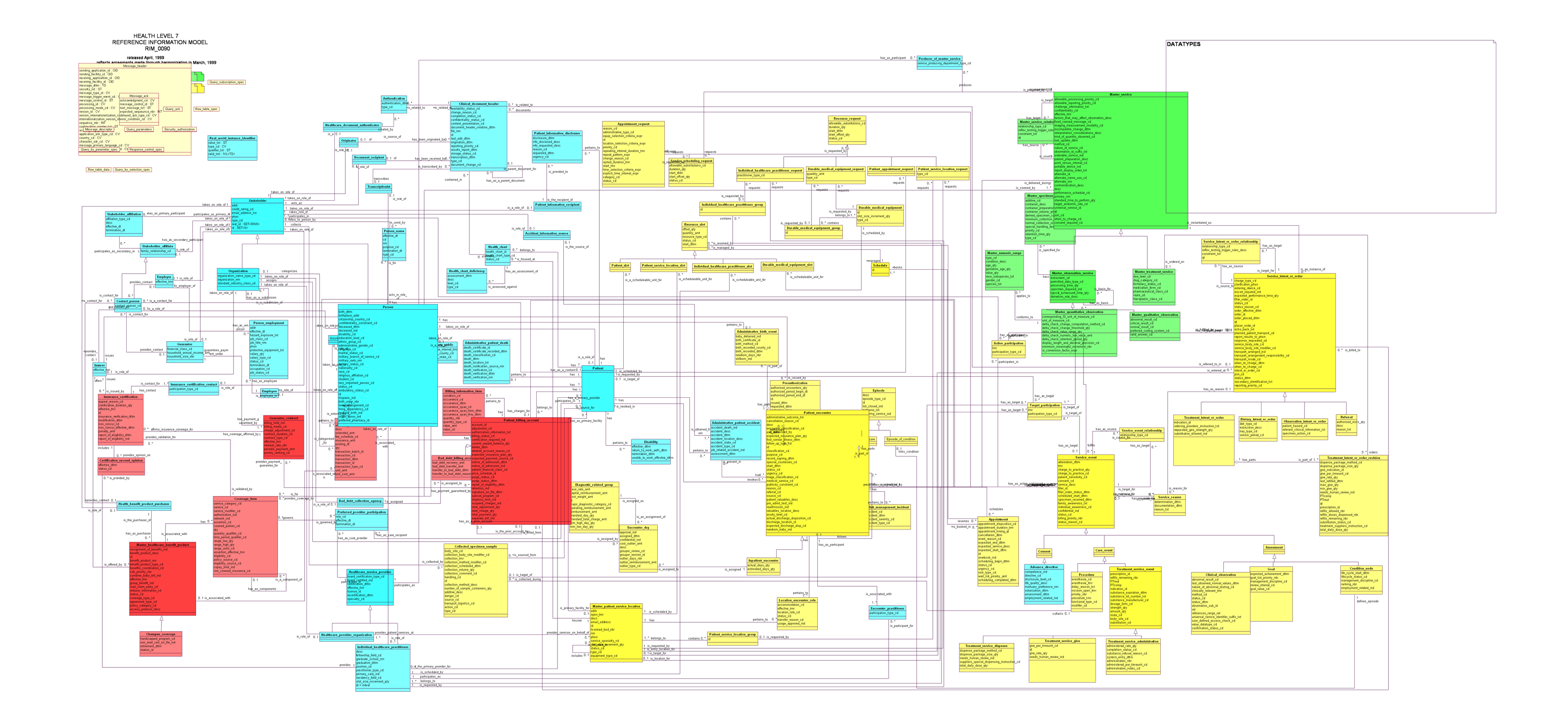
HL7 then iterated on these models in what they called “Harmonization Meetings” where they would discuss what a “common” model needed to look like. The RIM grew in each meeting, and soon became massive. It had over 130 classes, and over 980 attributes. “It would take one person almost 3 days to lay out the different connections in the RIM,” is how Woody Beeler described it.
HL7 RIM v0.9 as in 1999
To simplify it, the USAM II proposal (1999-2001) collapsed multiple clinical classes into a few concepts, Acts and Entities, and introduced the idea of “mood”. Abdul-Malik argued that the complexity wasn’t gone, just hidden, but the group accepted the simplification.
The Kona proposal and CDA
Meanwhile, another experiment took place in New Hampshire in 1997. A small group of vendors and physicians met at the Kona Mansion and prepared a document-first approach using XML. XML was brand new back then, only a year since its first release.
This initiative was absorbed into HL7 with much discussion, and became CDA or Clinical Document Architecture and C-CDA. These were the most widely adopted v3 artefacts, and are still in use today.
Adoption
In 2008 - 2011, many countries attempted to adopt v3 and CDA in their national programs. This included the NHS in England, Finland and the Netherlands. Implementers however, found the process complex.
The people and tooling weren’t there yet. Teams used to counting pipes in v2 now needed to use the domain model. And for hospitals the ROI wasn’t clear. v2 was still in use and needed to be supported, and v3 wasn’t backwards compatible.
v3 also didn’t have the same community engagement and support that v2 did, and so, there was less organic momentum.
By 2011, HL7 decided it was time to take a fresh look at things.
Part 4: A fresh start for HL7
HL7 launched the Fresh Look Task Force in 2011, led by Stanley Huff. Their objective was simple.
What would we do if we were starting with healthcare interoperability from scratch today?
The core idea was this: To keep the good parts (models, vocabs, modelling rigor), but make it web-friendly.
Two streams emerged:
CIMI or Clinical Information Modeling Initiative led by Stanley Huff. They built on openEHR archetypes to make shareable data models in ADL and UML.
Resources for Health led by Grahame Grieve. This eventually became FHIR.
Grahame Grieve’s “Resources for Health”
Grahame Grieve
Grahame Grieve, an Australian software engineer and HL7 veteran took a different approach. He asked,
What do implementers want?
He took inspiration from beyond healthcare and found inspiration in the Highrise API. It was a clean and RESTful CRM API with predictable URLs and clear resource structures. Grahame imagined healthcare a healthcare standard that worked the same way, small and composable resources that were accessible via REST.
Between May and August 2011, he wrote the first version of Resources for Health along with his day job. It was published on his blog, Health Intersections, in August 2011 and he asked for feedback from implementers. He emphasized simplicity, predictable URLs, open formats and community feedback.
The fall meeting of HL7 was in a few weeks, and Resources for Health was adopted. Marketing renamed it to FHIR, for Fast Healthcare Interoperability Resources. Grahame insisted on FHIR being open source, which was different from HL7’s usual licensing approach.
In 2012, the first FHIR connectathon was held, and the community was invited to build and test early implementations. Two years later, DSTU1, the first Draft Standard for Trial Use was released, and the wave of adoption began.
Why did FHIR succeed?
FHIR blended the rigor of v3 with the accessibility of the web. It kept formal data types, terminologies and value sets, but wrapped them in easy to use RESTful APIs. Extensions and profiles provided flexibility, and also ensured some structure and governance in how they were used.
Now with increased adoption, we do see some profile proliferation, but we’ve come a long way from the inconsistencies of v2.
In summary
Terminals → Messages → Models → Resources
Healthcare’s IT journey began with mainframe computers and terminals, evolved through messaging and modelling, and now thrives on web APIs.
Don Simborg proved at UCSF that systems could exchange data at Layer 7
HL7 v2 standardized those ideas into repeatable and affordable interfaces
Abdul-Malik Shakir brought structure and modelling discipline through v3 and RIM
Grahame Grieve distilled decades of lessons into small, elegant web-ready FHIR resources.
This story traces over 30 years of interoperability, driven by the pursuit of simple, open and universal ways to share health data.