

A History of HL7: From Terminals to APIs
A journey through 30 years of healthcare interoperability from costly 1980s interfaces to modern FHIR APIs following HL7's evolution to web-friendly resources.
May 29, 2026
FHIR (Fast Healthcare Interoperability Resources) is an open healthcare data standard from HL7 International. It defines how clinical and administrative health data (patients, observations, prescriptions, encounters) is structured and exchanged between systems using REST APIs, JSON, and XML.
First released in 2014 and currently on version R4, FHIR is mandated or formally advised in 15+ countries, including the United States under the 21st Century Cures Act according to the 2025 State of FHIR Survey. FHIR is the standard behind Apple Health Records. Most major EHR vendor APIs and a growing number of national health data platforms also use FHIR for interoperability.
In plain terms: FHIR is what lets your cardiologist’s system talk to your GP’s system without a fax machine in the middle, and lets developers build health apps without learning proprietary protocols from the 1980s.
The first health data interoperability “systems” were human. Nurses went from terminal to terminal to pull together a complete picture of a patient’s care. Later came “front-end networks” where one terminal could connect to multiple backends. It reduced effort, but did not address the actual problem: that systems couldn’t talk to each other.

The first software fixes carried a heavy price tag. In 1987, connecting a single lab system to a hospital’s mainframe would cost around $100,000. Every additional system needed another custom interface. And so to achieve interoperability, a hospital would need to have dozens of bespoke (and expensive) integrations.
This is the gap HL7 was created to fill. To understand FHIR, it helps to understand where it came from, and the 40 years of standards work before it.
In 1987, hospital CIOs, vendors, and academics met in Philadelphia to draft a standard for healthcare data exchange. This group became HL7, or Health Level 7. Their goal was to ship something workable, fast.
HL7 v1 came out the same year, and v2 followed in 1988. It dropped interface costs from $100,000 to $10,000. HL7 also marketed it heavily with live, interactive demos at conferences.
v2 message structure was simple. It had pipe-delimited text with every position carrying a fixed meaning.

It was good enough for most use cases, and as a bonus was fast and cheap. But there were two structural problems:
There’s a saying in health IT that captures this,
“Once you’ve seen one HL7 v2 implementation—you’ve seen one HL7 v2 implementation.”
HL7’s response to this was to start over with a single shared information model that all messages would derive from. The result was the Reference Information Model, or RIM, first compiled in 1996. By 1999 it had over 130 classes and 980 attributes.
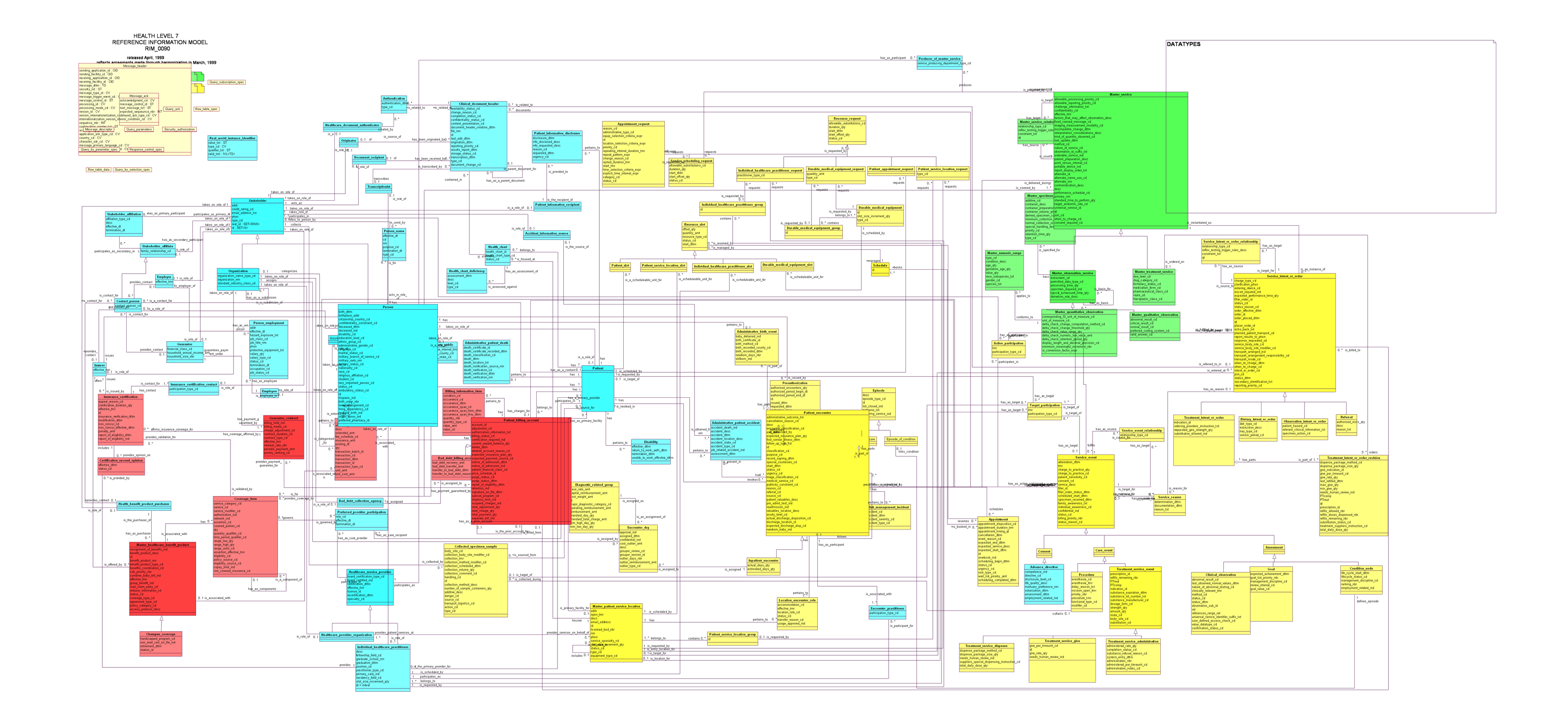
v3 failed to take off. Several countries tried to adopt it in their national programs between 2008 and 2011. Implementers found the process complex and the tooling wasn’t there. Importantly, v3 wasn’t backwards compatible, so for hospitals the ROI for switching was unclear.
One piece of v3 that succeeded was the Clinical Document Architecture or CDA. It used XML to define structured clinical documents
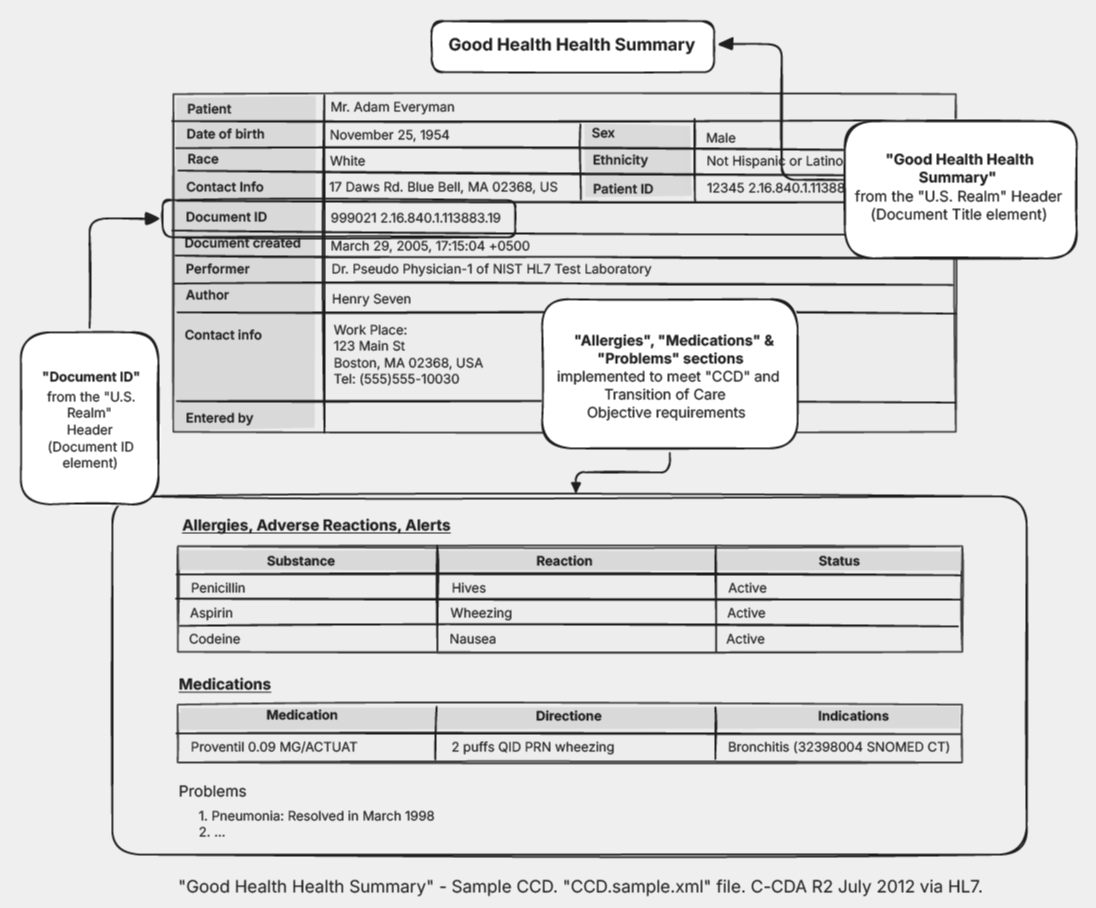
CDA and later C-CDA are the most widely adopted v3 artifacts. C-CDA was mandated under US Meaningful Use Stage 2 regulations and is still in use today.
HL7 launched the Fresh Look Task Force in 2011. The question they wanted to answer was: if we were starting healthcare interoperability from scratch today, what would we do?
Grahame Grieve, an Australian software engineer and HL7 veteran approached this as: what do implementers actually want? He looked outside healthcare and found his answer in modern REST APIs like Basecamp’s Highrise CRM: predictable URLs, clean REST, documentation you could read on the web. Between May and August 2011, alongside his day job, he wrote the first version of “Resources for Health.” HL7 adopted it at the fall meeting and renamed it FHIR.
Grahame insisted FHIR be published open source, a year before HL7 announced free licensing for its other standards. The first FHIR Connectathon ran in 2012. DSTU 1 was published in 2014. R4, the current normative version, landed in 2019. For the full history, including the pre-HL7 work at UCSF and the people who built each standard, see Medblocks’ A History of HL7: From Terminals to APIs.
FHIR’s design choices are what make it different from earlier HL7 standards. These principles do most of the work:
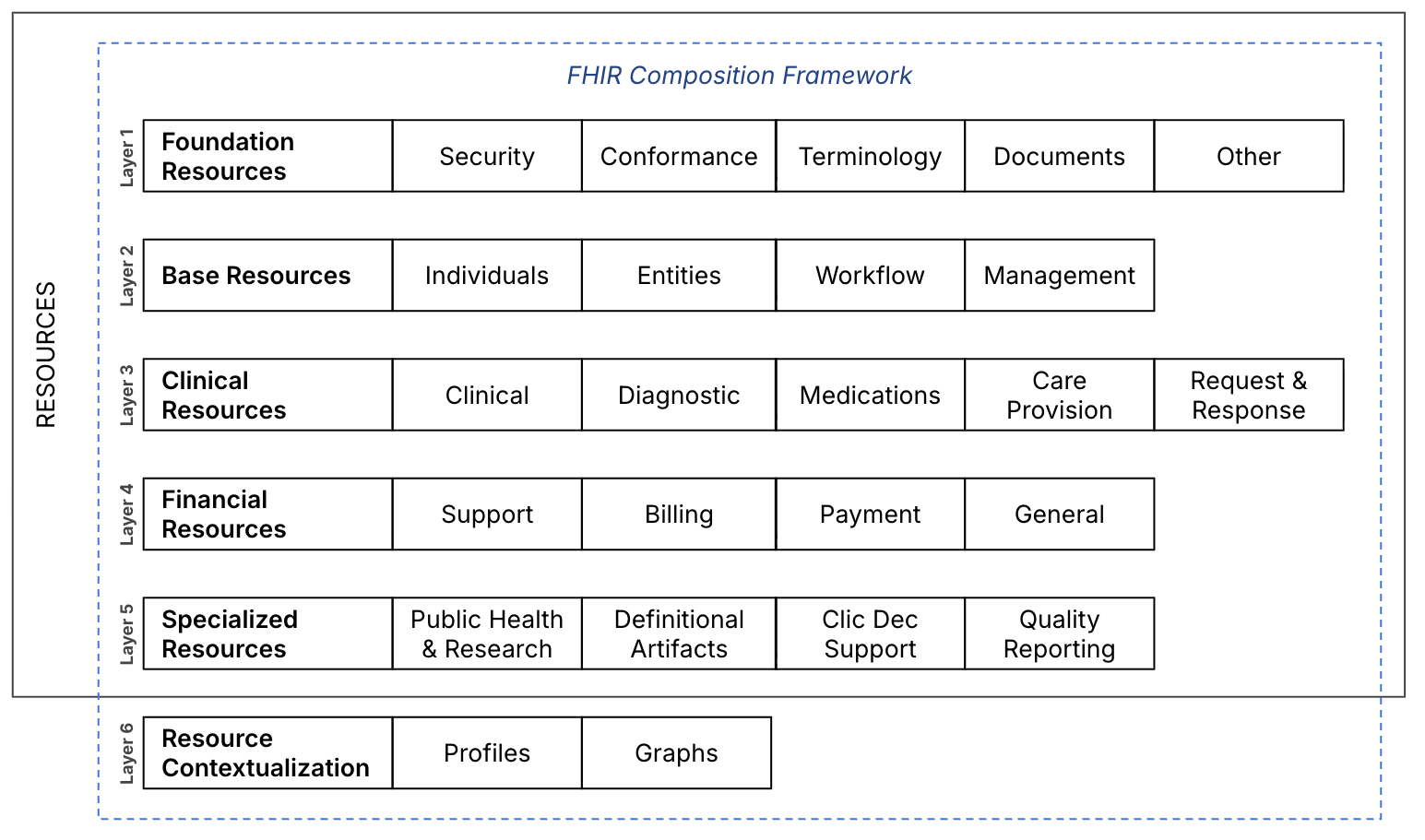
FHIR breaks healthcare data into small, independent units called resources. A Patient is a resource. An Observation is a resource. A MedicationRequest is a resource. Each one is structured, self-contained, and can stand alone or reference others.
This is a deliberate departure from v3’s RIM, which tried to model everything in one place. Modular resources are easier to implement, easier to version, and easier to extend. A developer can work with the Patient resource without learning the entire FHIR specification first.
FHIR uses HTTP, REST, JSON, and XML, the same stack behind every consumer web application. No proprietary protocols. No domain-specific tooling.
This sounds obvious now, but it wasn’t when FHIR was proposed in 2011. HL7 v2 ran on MLLP (Minimal Lower Layer Protocol), a transport designed specifically for healthcare messaging. v3 used SOAP and complex XML schemas. Both required specialist knowledge to implement.
FHIR’s choice to use REST and JSON meant any developer who could call a web API could call a FHIR API. This opened healthcare to a much wider pool of engineers than the previous standards had.
FHIR’s core specification covers what most healthcare systems need most of the time, and then stops. Everything specialized, jurisdiction-specific, or organizationally unique gets handled through profiles and extensions (covered later in this article).
This is often misunderstood as “FHIR captures 80% of all healthcare data.” It doesn’t. Grahame Grieve explains it carefully in The Principles of Health Interoperability (co-authored with Tim Benson): the 80-20 rule is about covering the elements and workflows that most people agree on, while keeping the standard small enough to be implementable. If every specialized requirement landed in the core, FHIR would become as unwieldy as v3.
A practical example: diagnostic reporting is largely uniform across healthcare. Most of its common features land in the “80%.” Care planning, by contrast, varies wildly between organizations and specialties. For care planning, FHIR provides a framework, not a prescription, and extensions fill in the rest.
The FHIR community has a shorthand for what this design enables. It’s known as the 5-5-5 rule:
The fourth line is the punchline. FHIR makes the technical entry point easy.
The resource is a central concept in FHIR. It is the smallest unit of exchangeable healthcare information: a structured, self-contained document representing one specific clinical or administrative entity.
FHIR R4 defines 145 resources. R5 added more, bringing the total to 157. Most production systems target R4.
| Resource | What It represents | | ----- | ----- | | Patient | Demographics: name, date of birth, gender, address, identifiers | | Practitioner | A healthcare provider: doctor, nurse, pharmacist, therapist | | Encounter | A visit or interaction between a patient and a provider | | Observation | A clinical measurement: blood pressure, lab result, BMI, vital sign | | Condition | A diagnosed problem, illness, or health concern | | MedicationRequest | A prescription: drug ordered, for whom, by whom, and when | | Medication | A drug or pharmaceutical product | | AllergyIntolerance | A documented allergy or adverse reaction | | DiagnosticReport | A formal report from a diagnostic test (MRI, pathology, lab panel) | | Immunization | A vaccine administered to a patient | | Procedure | A clinical procedure performed on or for a patient | | Organization | A healthcare facility, payer, or administrative entity |
Most applications use these resources.
A minimal Patient resource in JSON:
{
"resourceType": "Patient",
"id": "patient-001",
"identifier": [
{
"use": "official",
"system": "http://hospital.example.org/patients",
"value": "12345"
}
],
"name": [
{
"use": "official",
"family": "Doe",
"given": ["John", "A"]
}
],
"gender": "male",
"birthDate": "1980-01-01",
"address": [
{
"line": ["123 Main St"],
"city": "Anytown",
"state": "CA",
"postalCode": "90210"
}
]
}
The resourceType field is always required, it tells the system exactly what kind of resource this is. Every Patient resource will carry "resourceType": "Patient" at all times.
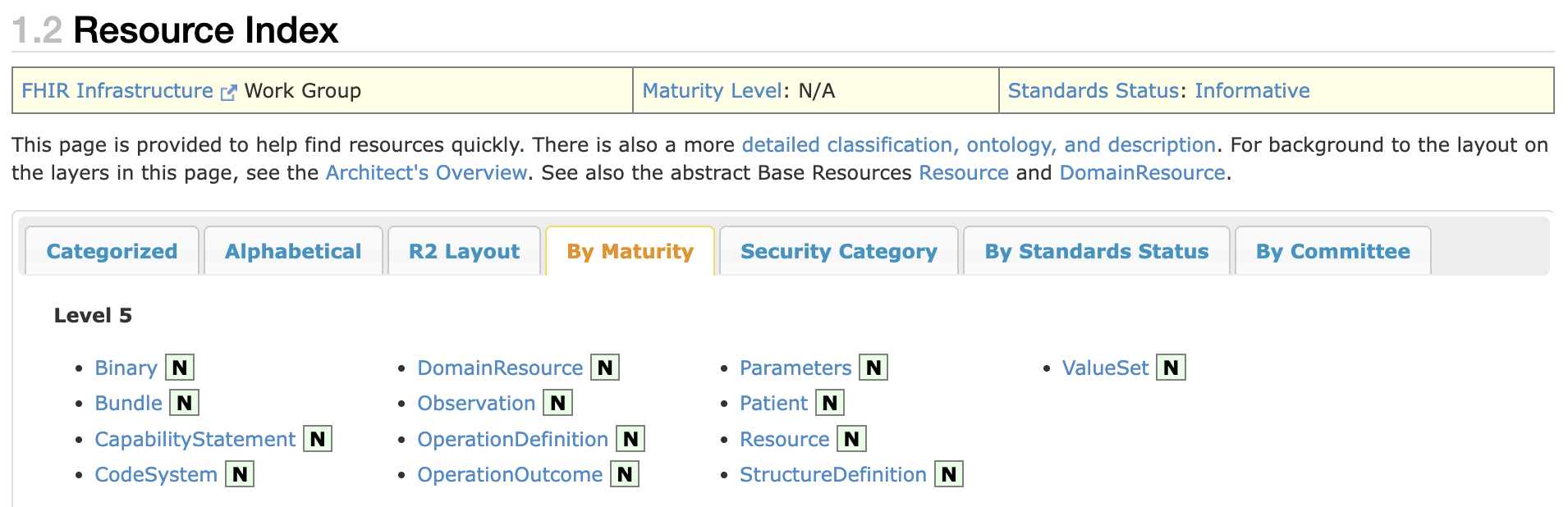
Not every resource is equally stable. FHIR assigns each one a maturity level from 0 to 5 (or N for normative). Higher means more battle-tested.
For production, stick to Level 3 and above. Patient, Observation, and MedicationRequest are all normative, safe to build against.
Each field in a FHIR resource has a defined data type. Some are primitive (simple values), others are complex (nested structures with multiple fields).
Primitive types include string, boolean, integer, decimal, uri, dateTime, and code. These are exactly what they sound like.
Complex types carry richer structure. These are the ones you will see constantly:
The FHIR specification covers this in detail.
Every field in a FHIR resource has a cardinality — the minimum and maximum number of times it can appear, written as minimum..maximum.
0..1 optional, appears at most once1..1 required, appears exactly once0..* optional, can appear many times1..* required, appears at least onceA * means “as many times as needed.” The identifier field on a Patient has cardinality 0..*, so it can have zero identifiers or dozens. The resourceType field has cardinality 1..1 and so it is always present, exactly once.
FHIR has gone through several major versions since 2014. Here are the key versions to know.
| Version | Released | Status | | ----- | ----- | ----- | | DSTU 1 | 2014 | First official release. Mostly used for testing and feedback. | | DSTU 2 | 2015 | Expanded resource set, more real-world implementations. | | STU 3 | 2017 | Significant maturation. Many early production systems built on this. | | R4 | 2019 | Normative release. Core resources are stable, no breaking changes. | | R4B | 2022 | A patch on R4 with new resources for drug regulation and evidence-based medicine. Not Cures Act compliant. | | R5 | 2023 | Adds new resources and refinements. Still being adopted. |
Unlike many web standards that version the API separately from the data model, FHIR versions both together. A new release like R4 or R5 covers updated core API rules (how to interact with resources via REST) and updated resource definitions in the same package.
Grahame Grieve has explained the reasoning in interview: a small change to a resource can indirectly affect how clients and servers interact, so cleanly separating API versioning from resource versioning isn’t practical. They move together.
R4 (specifically version 4.0.1) is what US regulatory requirements mandate, every major EHR vendor’s API implements, and where the largest deployment base sits. The core is stable with no breaking changes to normative elements.
R4B is not a substitute. Despite the name, it’s a patch release for specialized use cases in drug regulation. The US Cures Act explicitly requires R4, not R4B: implementations targeting R4B are not compliant.
R5 is published and adoption is starting, but R4 will remain the production standard for most use cases.
The base FHIR specification covers the common case. But healthcare is not uniform. A patient record in the United States has different mandatory fields than one in Germany. A cardiology system needs to capture data that a GP’s practice never touches.
FHIR handles this without fragmenting the standard through two mechanisms: Profiles and Extensions.
A profile is a set of constraints applied to a base FHIR resource to meet specific requirements. Profiles can:
The US Core profile defines exactly which fields US-based systems must support for Patient, Condition, Observation, and other resources to meet federal regulatory requirements. The US Core Patient profile, for example, adds fields like race and ethnicity that aren’t in the base international specification.
Different countries publish their own profiles for the same reasons. India has ABDM, Saudi Arabia has nphies, Australia has AU Core. Each one constrains the base FHIR resources to fit local rules and workflows.
Profiles distinguish between two kinds of required elements, and the difference matters in practice.
Must Support elements (marked with a red “S” flag in the spec) mean that systems must be able to process and handle the element when it is present. They don’t have to always include it, but they cannot ignore it.
Mandatory elements have a cardinality minimum of 1. They must always be present. You cannot omit them from a valid resource.
Sometimes you need a field that does not exist in the base resource. Extensions are how FHIR handles this. Each extension has a unique URL identifier and can carry any data type allowed in FHIR. They can even contain nested sub-extensions.
An extension for patient race might look like this:
{
"url": "http://hl7.org/fhir/us/core/StructureDefinition/us-core-race",
"extension": [
{
"url": "ombCategory",
"valueCoding": {
"system": "urn:oid:2.16.840.1.113883.6.238",
"code": "2054-5",
"display": "Black or African American"
}
}
]
} The combination of profiles and extensions means a FHIR resource can carry highly specialized clinical data while any FHIR-compliant system can still read and process the base fields, even if it doesn’t understand the extensions.
Defining resources is only half the picture. FHIR also specifies how resources are exchanged. The specification defines six paradigms. Three handle most real-world traffic.
REST is by far the dominant paradigm in FHIR. The URL pattern is predictable:
GET [base]/Patient/123 → Read a patient
GET [base]/Patient?name=Doe → Search patients
POST [base]/Patient → Create a patient
PUT [base]/Patient/123 → Update a patient
DELETE [base]/Patient/123 → Delete a patientThis is the paradigm major EHR vendors (Epic, Oracle Health, Athena) expose to third-party developers. SMART on FHIR (covered later) layers OAuth 2.0 authorization on top so apps can securely request specific patient data with user consent.
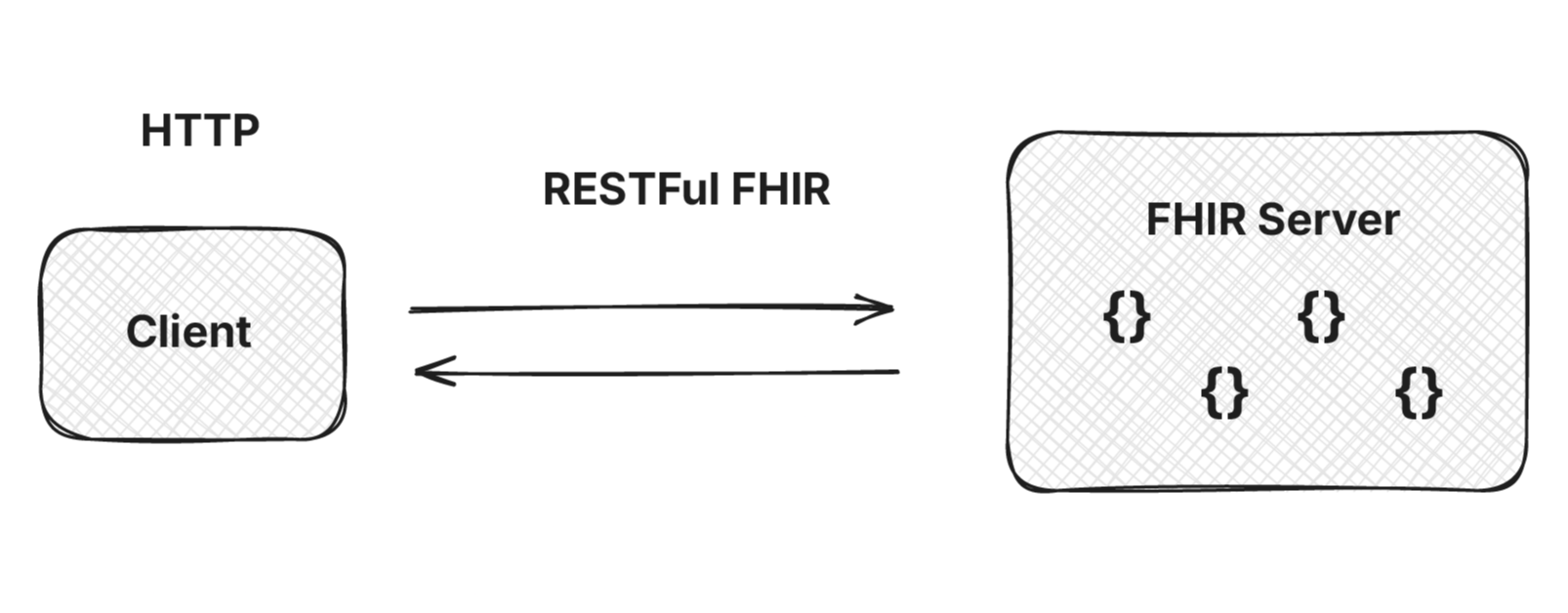
REST works well for accessing small amounts of data, but population-scale exports break it. Pulling clinical data for 10,000 patients one resource at a time means hundreds of thousands of API calls.
Bulk Data Access (also called Flat FHIR) solves this. It’s a separate implementation guide built on REST that defines an asynchronous pattern: a client kicks off an export operation, polls for status, and downloads the result as newline-delimited JSON (ndjson) files when ready.
Bulk Data is used for population health, payer-provider data exchange, public health surveillance, and quality measure reporting. CMS now requires Bulk Data support in several federal interoperability rules, including the Prior Authorization Final Rule.
A FHIR Document Bundle is a collection of resources packaged as a single, complete clinical document. Every document bundle includes a Composition resource, which defines the document’s structure and acts as a table of contents, along with all the resources it references, embedded in the bundle.
Document bundles are used for discharge summaries, referral letters, and clinical notes — anywhere a complete, standalone clinical document is needed. They preserve the integrity of the document as a whole, which matters for legal and clinical record-keeping.
FHIR Messaging is designed for event-driven workflows where actions need to trigger when something happens. It uses a MessageHeader resource to define the purpose of the message, and supports request/response patterns with acknowledgement and reliable delivery.
Saudi Arabia’s nphies platform uses FHIR Messaging extensively for health insurance transactions — prior authorization, claims submission, and adjudication.
The Services paradigm covers complex operations invoked through FHIR servers. The most prominent example is CDS Hooks, a standard for real-time clinical decision support inside the EHR.
When a clinician opens a patient chart, prescribes a medication, or signs an order, the EHR fires a webhook to an external CDS service. The service returns cards, small UI elements with relevant alerts, recommendations, or links to a SMART on FHIR app for a deeper workflow. It’s how things like drug-interaction warnings, duplicate-test alerts, and population-health flags can be added to an EHR without rebuilding the EHR.
CDS Hooks adoption is growing in the US, particularly with payer-provider use cases under CMS Interoperability and Prior Authorization rules. For a deeper look, see this article, CDS Hooks Matter More Than You Think.
A FHIR Implementation Guide (IG) is the full package: profiles, extensions, exchange paradigms, value sets, and detailed documentation combined into a single blueprint for a specific interoperability goal.
Here is a useful mental model:
FHIR IG = FHIR Profiles + Extensions + Exchange Paradigm + Documentation
IGs serve as the contract between implementers. When a government or health system says “implement FHIR,” what they almost always mean is “implement this specific IG.” Pure base-FHIR compliance is necessary but not sufficient, the IG is what defines what your system actually needs to do.
Some IGs worth knowing:
The HL7 FHIR IG Registry is the central repository for published implementation guides. You can search by country, jurisdiction, or use case. This is a useful starting point when entering a new market or regulatory context.
The history section above explains how we got to FHIR. Here is a practical comparison.
| Feature | HL7 v2 | HL7 v3 / CDA | FHIR | | ----- | ----- | ----- | ----- | | Format | Pipe-delimited text | XML (RIM-based) | JSON / XML / Turtle | | Protocol | MLLP (proprietary) | HTTP/SOAP | HTTP (REST) | | Specification access | Freely available (Paywalled till 2013) | Freely available (Paywalled till 2013) | Freely available | | Learning curve | High (specialist) | Very high | Low (standard web skills) | | Consistency | Low (Z-segments) | High but complex | High, with profile flexibility | | Developer tooling | Sparse | Sparse | Rich and growing | | Mobile / web native | No | No | Yes | | Open source servers | Few | Few | Many (HAPI, Azure, Google, AWS) | | Community / events | Small specialist | Small | Large, diverse (Connectathons, DevDays) | | Regulatory mandates | No | No | Yes, 15+ countries |
One thing worth singling out is FHIR’s open-source nature. While HL7 v2 and v3 specifications were paid until 2013, FHIR was free from the start. That single decision is what made educational content, open-source servers, and community tooling possible.
The most common question after “what is FHIR” is “how does it compare to openEHR.” They’re often presented as competitors. In practice, they solve different problems.
FHIR is built for data exchange. It defines how healthcare data is structured and moved between systems using REST APIs and JSON. Profiles and extensions adapt the base spec to local requirements.
openEHR is built for clinical modeling and long-term storage. It separates clinical content models (called archetypes) from technical implementation. Archetypes are designed and reviewed by a global clinical community, then deployed across systems. So “blood pressure” means the same thing in any openEHR-based system, anywhere in the world.
| | FHIR | openEHR | |---|---|---| | Primary purpose | Data exchange | Clinical modeling and storage | | Strongest at | APIs, interoperability, app development | Semantic precision, long-term data integrity | | Modeling layer | Profiles applied to base resources | Archetypes governed by global clinical community | | Regulatory traction | US Cures Act, EU EHDS, India ABDM, 15+ countries | Norway, Finland, Slovenia, parts of Brazil and India | | Typical role | Exchange between systems | Underlying clinical record |
Increasingly, organizations use them together. openEHR for the clinical record system that captures and stores data, FHIR for the exchange layer that moves data out to apps, patients, and external systems. The two standards address different layers of the same problem.
Choosing between them isn’t really the right framing. The better question is which layer of your architecture each one belongs in.
We’ll cover this in depth in a separate guide.
Most standards look good on paper and die in obscurity. FHIR didn’t. Grahame has pointed to three specific milestones that made the difference.
When the major US EHR vendors, Epic, Cerner (now Oracle Health), Athena, committed to building FHIR APIs for patient and provider access, the ecosystem had its anchor. Regulatory pressure from ONC was building, but the decision to standardize on FHIR rather than proprietary APIs was the inflection point. The Argonaut Project, an industry-led IG that preceded US Core, was where this alignment happened.
Convincing the HL7 board to drop the license fee was not easy. But once the specification was free to read and implement, the educational content and open-source tooling followed immediately. HAPI FHIR, the most widely used open-source Java FHIR server, would not exist under the old licensing model. As we covered earlier, this happened a year before HL7 announced free licensing for its other standards in September 2012.
When Apple launched Health Records in January 2018 with iOS 11.3, it built the feature on standard FHIR and SMART on FHIR, no Apple-specific modifications. The first release connected 12 US hospitals; today it connects hundreds. The signal was unmistakable: a consumer technology company would build on the standard as-is, not fork it.
One thing about FHIR that is underappreciated is the community.
A FHIR Connectathon is like a hackathon, but the focus is on connecting different systems together rather than building new things independently. These events bring clinicians, developers, policy makers, and vendors into the same room to test interoperability in real time.

FHIR DevDays is the flagship community event, a multi-day conference drawing attendees from across the global FHIR ecosystem. The energy of these events reflects something real: FHIR has created a genuine cross-disciplinary community in a field that historically kept developers, clinicians, and policy makers completely separate.
Firely and Health Samurai have been particularly active in building and sustaining this community alongside HL7.
FHIR’s adoption is not a US story. According to the 2025 State of FHIR Survey by HL7 International and Firely, 78% of countries surveyed have regulations governing electronic health data exchange — and 73% of those regulations either mandate or advise FHIR. That figure has climbed from 56% in 2023.
The countries where FHIR has been formally mandated or advised in national regulation:
Many more countries including the UK, Australia, Canada, and most of the EU, have strong FHIR adoption programs without reaching the level of legal mandate yet.
Enforcement is uneven. The 2025 survey found that only about 50% of these regulations include formal compliance deadlines, and just 12-16% impose penalties for non-compliance. Saudi Arabia and Estonia are among the few enforcing national deadlines.
Generic FHIR servers like HAPI FHIR, Smile CDR, and commercial platforms from Google, Microsoft, and AWS can load resource definitions dynamically, which means you can update data models without completely rewriting server logic. Once you move into meaningful processing like, business rules, clinical decision support, and complex queries, developers typically find it easier to reference resource elements directly in code rather than relying on dynamic loading.
A pattern emerging across health IT is organizations storing their healthcare data natively in FHIR. The logic seems straightforward: if you already use FHIR for exchange, why not use it for storage too?
Grahame Grieve has addressed this directly in The Principles of Health Interoperability. FHIR was designed for data exchange, not as a database storage format. Its resource structure is organized for flexibility and shareability, not for fast, complex queries or large-scale transactional workloads.
That said, there are scenarios where FHIR-native storage works well:
In practice, FHIR often expands beyond its intended exchange role, what data scientist Daniel Kapitan, calls “standard leakage.” In his work on Health Information Exchanges in Kenya and Tanzania with PharmAccess, Daniel found FHIR being used across three layers at once: as the system of record for point-of-care apps, as the exchange format between services, and as the warehousing substrate for bulk exports. Local startups like Ona’s OpenSRP were already building FHIR-native, and Google’s Open Health Stack (Android FHIR SDK, FHIR Analytics) made end-to-end FHIR adoption easier than mixing standards.
The takeaway: once a standard works in one layer, it tends to leak into the others, driven by developer familiarity, ecosystem support, and the cost of training teams on multiple standards. Read the full discussion here.
The most common confusion in real implementations: treating a FHIR shared health record as a data warehouse. These are different things.
A shared health record is transactional. It tracks individual patient data in real time and supports day-to-day clinical workflows. A data warehouse is analytical. It aggregates data across patients and encounters for dashboards, monitoring, and population-level analysis.
Questions like “show me all patients who haven’t returned for a visit” require analytical workflows that transactional FHIR servers aren’t designed to handle. For analytics, bulk exports moving into purpose-built systems like SQL on FHIR, ClickHouse, or similar. work better than running expensive queries against the live FHIR store.
Most cloud providers now offer managed FHIR storage:
Open-source options include HAPI FHIR (Java) and Smile CDR. Both can load resource definitions dynamically, which means you can update data models without completely rewriting server logic. Once you move into meaningful processing (business rules, clinical decision support, complex queries) developers typically find it easier to reference resource elements directly in code rather than relying on dynamic loading.
Performance benchmarks vary widely depending on workload. Smile CDR has demonstrated 11,000 FHIR resources per second ingestion and 255,000 interactions per second on AWS infrastructure. Google Cloud Healthcare API has sustained 50 million synthetic patient records (around 26 billion resources) with per-resource response times under 200ms. Independent comparative benchmarks remain scarce, vendor numbers are useful but should be interpreted in context.
For a deeper look at what building FHIR-first looks like in production, see Medblocks’ conversation with Health Samurai on What does it take to build a FHIR-first EHR?. For an alternative approach using NoSQL infrastructure, see Couchbase x Medblocks: Building a NoSQL FHIR Server.
SMART on FHIR (Substitutable Medical Applications and Reusable Technologies) is an open standard that layers OAuth 2.0 authorization on top of FHIR APIs. Think of it as “sign in with your hospital” for health applications.
Without SMART, a FHIR API might be accessible but unsecured, or require complex custom authentication arrangements between organizations. SMART defines:
If you’re building a clinical app that needs to pull a patient’s medication list from their hospital EHR, SMART on FHIR is the mechanism that makes it work with proper user consent, appropriate scope limits, and standard token-based authentication.
Major EHR vendors all support SMART on FHIR. The US Core Implementation Guide requires it. Epic’s Showroom marketplace (formerly App Orchard) hosts over 1,000 apps that integrate with Epic systems, most of them via SMART on FHIR. Since Showroom launched, monthly FHIR API calls on Epic alone have grown from about 6 billion to over 10 billion.
Your existing skills transfer. FHIR APIs respond to standard HTTP — test them with Postman or curl, call them from Python, JavaScript, Go, or Swift. No proprietary SDKs required.
Open-source servers are ready to use. HAPI FHIR (Java) is the most widely deployed open-source FHIR server, and its public test instance at hapi.fhir.org/baseR4 accepts real requests without any setup. Send a GET to /Patient and you’ll get back real FHIR data.
Client libraries exist for most languages. fhir.resources in Python, fhir.js for JavaScript, the HAPI FHIR client for Java, Microsoft’s FHIR SDK for .NET — all maintained and production-ready.
Building clinical data collection? The FHIR Questionnaire resource is your starting point. It defines structured forms and captures responses in a FHIR-compatible format, no custom schema needed.
Build against FHIR R4. It’s what every major EHR API supports, what HAPI FHIR’s stable releases target, and what the 21st Century Cures Act explicitly requires for US compliance. R4B is a patch release for specialized drug regulation use cases and is not Cures Act compliant. R5 is published but adoption is still early.
Implement against the profile, not the base spec. The US Core IG is your target for US healthcare, ABDM for India, AU Core for Australia. “FHIR compliance” at the base resource level isn’t enough, the profile defines what your system actually has to do.
US compliance isn’t optional. Not having FHIR APIs is a regulatory violation for covered health systems and EHR vendors under the 21st Century Cures Act. Quality of implementation is the real differentiator.
Beyond the US, FHIR mandates apply in India (ABDM), Germany (DigiG and ISiK), Brazil (RNDS), Saudi Arabia (nphies), and more than ten other countries. Vendors operating across borders face compliance requirements in multiple jurisdictions, often with different profiles and Implementation Guides.
Patient access changes the conversation. When patients can pull their own records into apps, medication lists, lab results, immunization history, engagement improves. Apple Health Records connects hundreds of US hospital systems through FHIR, and similar models are spreading globally.
Care coordination gets architecturally easier. When a patient moves between primary care, a specialist, and a hospital, FHIR APIs let their data move with them, without custom point-to-point integrations for every system pair.
Standardized data collection improves analytics over time. Profiles reduce variation in how the same clinical concept gets recorded across systems, which matters for population health, quality reporting, and AI model training.
Most FHIR projects don’t fail because the standard is wrong, they fail because of avoidable implementation mistakes. The most common ones:
A system that returns valid FHIR resources is not necessarily interoperable. Two systems can both be “FHIR compliant” at the base resource level and still fail to exchange data, because they implement different profiles, value sets, or extensions.
FHIR’s flexibility is what makes it adoptable, and also what makes it easy to fragment. Success depends on choosing the right Implementation Guide for your jurisdiction or use case and following it consistently, not just claiming compliance at the resource level.
Newer isn’t better when compliance is on the line. R5 (2023) and R4B (2022) both exist and look like upgrades, but neither is a substitute for R4 if you’re building for US healthcare.
The 21st Century Cures Act mandates FHIR R4, specifically version 4.0.1 for certified EHR technology. R4B is a specialized patch release for drug regulation and evidence-based medicine. R5 adds new resources and refinements but isn’t required by any major regulatory framework yet. Apps built against either won’t pass US certification.
If your target is US healthcare, build against R4. R5 is worth tracking for future migration but not yet for production.
Profiles distinguish two kinds of required elements, and they mean different things. Mandatory elements (cardinality minimum of 1) must always be present. Must Support elements only require that your system can process them when present, they don’t always have to be included.
Treating Must Support as Mandatory leads to over-engineering and incomplete data. Treating Mandatory as Must Support leads to validation errors and failed integrations.
A FHIR server is a transactional system, not an analytics platform. Running complex aggregate queries against a live FHIR store “show me all patients with uncontrolled diabetes” works at small scale and breaks at production scale.
The pattern that works: use the FHIR server for day-to-day clinical workflows, and bulk-export data into purpose-built analytical systems (SQL on FHIR, ClickHouse, or similar) for population queries and reporting.
FHIR’s base specification doesn’t define what “blood pressure” or “fever” means clinically. The same concept can be modeled differently across IGs and across vendors using the same IG. Data that looks syntactically valid in FHIR may not be semantically comparable across systems.
Joost Holslag, a Dutch health informatics consultant, in a conversation hosted by Medblocks, calls this “semantic debt” low quality of initial data capture creates interoperability problems that compound as systems grow. Some teams address it by mapping to openEHR archetypes or other shared semantic models. Others handle it with focused, use-case-specific transformations and ICD-10 mappings.
The general principle: FHIR’s structural compliance doesn’t guarantee semantic interoperability. Plan for the semantic layer separately.
Reading the full FHIR specification at hl7.org/fhir is valuable but overwhelming as an entry point. A more effective path:
Start at hl7.org/fhir/summary.html. Understand resources, data types, and the REST API at a high level before diving into specific resources.
Hit the public HAPI FHIR test server: GET https://hapi.fhir.org/baseR4/Patient. You’ll get back real FHIR data immediately. That concrete experience anchors the abstract concepts faster than reading more spec pages.
Patient, Observation, and MedicationRequest cover the majority of clinical scenarios. Read their spec pages, understand their fields, and practice creating examples in JSON.
For US healthcare: US Core IG. For India: ABDM IG. For Saudi Arabia: nphies IG. For Germany: ISiK. Your national or domain IG is your actual implementation target, not the base FHIR spec.
Reading the spec and sending test requests will only take you so far. The fastest way to learn FHIR is to build with it.
Medblocks runs the FHIR App Challenge, a 15-day program where you build a working Patient Management App on real FHIR APIs from Epic, Cerner, Athena, and eClinicalWorks. Coding and no-code tracks available, $27 entry with a money-back guarantee, over $25,000 in prizes, plus live kick-off and Demo Day webinars and a private Slack community.
If you’d rather start with the fundamentals first, the free FHIR Fundamentals course covers core resources, data types, profiles, exchange paradigms, and how to deploy your own FHIR server, with video walkthroughs and hands-on exercises.
Condensed for quick reference and for anyone building on FHIR.
FHIR is REST and JSON applied to healthcare. If you’ve built or consumed web APIs, the technical model is familiar. The learning curve is healthcare domain knowledge, not the technology.
Resources are the core unit. Patient, Observation, MedicationRequest, Encounter, learn around a dozen core resources and you can handle most integration scenarios.
Build against R4. It’s the normative standard, the US regulatory target, and the version every major EHR vendor API implements. R4B and R5 are not substitutes for production use.
The 80-20 rule is about adoption, not completeness. FHIR covers what most systems need most of the time. Profiles and extensions handle the specialized rest without fragmenting the standard.
Open-source was the decisive factor. Free licensing is what allowed the educational content, open-source servers, and developer ecosystem to grow faster than any proprietary standard could have.
SMART on FHIR is the authorization layer. If you’re building a health app that connects to EHR data, SMART on FHIR is what makes secure access possible.
Implementation Guides are your real target. Base FHIR compliance isn’t enough. US Core, ABDM, ISiK, nphies, AU Core, whichever IG applies to your jurisdiction is the actual contract you’re implementing against.
FHIR for storage is a choice, not a default. FHIR was designed for exchange. Using it for primary storage can work in high-change environments, but most production systems benefit from a hybrid approach with separate transactional and analytical layers.
FHIR is mandated or advised in 15+ countries. This is a global regulatory trend, not just a US story. Vendors operating internationally face compliance across multiple jurisdictions and IGs.
Start with hands-on exploration. Send a real API request to a HAPI test server before you finish reading the spec. Concrete experience accelerates learning faster than anything else.
Reading about FHIR will only take you so far. The fastest way to learn is to build something real with it.
Build your first FHIR app in 15 days. Medblocks’ FHIR App Challenge is a structured 15-day program where you build a working Patient Management App on real FHIR APIs from Epic, Cerner, Athena, and eClinicalWorks. Coding and no-code (Lovable) tracks both available.
Want to learn the basics first? The free FHIR Fundamentals course covers core resources, data types, profiles, exchange paradigms, and how to deploy your own FHIR server — with video walkthroughs and hands-on exercises.
Start with FHIR Fundamentals →
Last updated: May 2026. FHIR® is the registered trademark of Health Level Seven International (HL7). Use of these trademarks does not constitute an endorsement by HL7.
FHIR stands for Fast Healthcare Interoperability Resources, pronounced "fire." It's an open healthcare data standard from HL7 International that defines how clinical and administrative data is structured and exchanged between systems using REST APIs, JSON, and XML.
Grahame Grieve, an Australian software engineer and HL7 veteran, conceived FHIR in 2011. He proposed "Resources for Health" — inspired by the Highrise CRM API — and pushed for HL7 to publish it under an open-source license. The first official release (DSTU 1) came in 2014. He is widely known as the "father of FHIR."
A FHIR resource is the smallest unit of exchangeable healthcare information — a structured, self-contained document representing one clinical or administrative entity. Examples include Patient, Observation, MedicationRequest, and Encounter. Every FHIR resource includes a resourceType field declaring what kind of resource it is.
HL7 (Health Level Seven International) is the organization that publishes healthcare data standards. FHIR is the most current of those standards. HL7 also developed HL7 v2 — a pipe-delimited messaging format still running in most hospital systems — and HL7 v3, a complex XML standard that largely failed to gain adoption. FHIR is HL7's modern REST-based replacement.
Build against FHIR R4 (released 2019). R4 is the version US regulatory requirements specifically mandate under the 21st Century Cures Act, the version every major EHR vendor API implements, and the version with the largest deployment base. R4B and R5 exist but neither is required by any major regulatory framework — R4B is a specialized patch release, and R5 adoption is still early.
FHIR R4 (2019) is the current production standard for healthcare interoperability. It's normative — its core resources are stable with no breaking changes. R5 (2023) adds new resources and refinements but isn't yet required by major regulations. For US Cures Act compliance, you must build against R4 specifically. R5 is worth tracking for future migration but not yet for new production systems.
Yes, for covered entities. The 21st Century Cures Act and ONC's interoperability rules require certified EHR vendors and health information networks to support FHIR R4 APIs for patient data access. "Information blocking" — preventing patient access to this data — carries financial penalties.
Yes. FHIR is published under an open-source license at no cost. The full specification is available at hl7.org/fhir. This was a deliberate choice — Grahame Grieve insisted on open-source licensing when HL7 adopted FHIR, a year before HL7 announced free licensing for its other standards in 2012. The decision is widely credited as one of the main reasons FHIR succeeded.
SMART on FHIR is an open standard that adds OAuth 2.0 authorization to FHIR APIs. It lets third-party applications securely request specific patient data with user consent, and defines how apps launch from within an EHR (EHR launch) or from an external browser (standalone launch). Most major EHR vendors support SMART on FHIR. If you're building a health app that connects to hospital EHR data, SMART on FHIR is the authorization layer you need.
A FHIR profile is a set of constraints applied to a base resource to meet specific requirements. Profiles can make optional fields required, restrict value sets, and add new fields through extensions. The US Core profile defines which fields are mandatory for FHIR-based systems operating under US regulatory requirements. Other examples include ABDM (India), ISiK (Germany), and nphies (Saudi Arabia).
Any language that can make HTTP requests works with FHIR APIs — they're standard REST. Maintained client libraries exist for Python (fhir.resources), JavaScript (fhir.js), Java (HAPI FHIR client), .NET (Microsoft FHIR SDK), Go, Ruby, and Swift.
A FHIR Implementation Guide (IG) is the full interoperability specification for a particular use case or jurisdiction — profiles, extensions, value sets, exchange paradigms, and documentation packaged together. When a government or health system says "implement FHIR," they almost always mean "implement this specific IG." The HL7 FHIR IG Registry at registry.fhir.org is the central repository.
A journey through 30 years of healthcare interoperability from costly 1980s interfaces to modern FHIR APIs following HL7's evolution to web-friendly resources.
EHR sidecars have a long history of filling gaps that core EHRs couldn't. Learn how sidecars started, evolved, and why they're still relevant today.
Learn how SMART on FHIR connects apps to EHRs using FHIR APIs and OAuth2. Covers launch flows, scopes, Epic and Cerner setup, SMART v2, and building your first app.
No comments yet. Be the first to comment!
