
The Data Warehouse is openEHR's Strongest Use Case Right Now
Why openEHR works better as a silver layer in your data warehouse than as a CDR, and what that means for clinical data at scale.
March 5, 2026
This article is a written version of my talk at EHRCON 25. Watch the full talk here:
This thought keeps me up at night:
What if we’re all making healthcare IT more complex than it needs to be?
In healthcare, we tend to assume that a lot of abstraction, tooling and layers are necessary to preserve clinical meaning. But what if the opposite is true? What if the solution to health IT complexity lies in using something as simple and powerful as SQL?
In this article, I document the complete argument from my talk, including the controversial parts.
Let me begin with a fundamental question: What are we actually building?
We’re not just building data standards, we are building data platforms to serve healthcare data in all its complexity.
I highly recommend reading the book Designing Data-Intensive Applications by Martin Kleppmann. It’s one of the most important books for anyone working with data systems. The ideas I’m going to explore in this article are based on my takeaways from this book.

Basically, any serious data platform must satisfy three criteria:
Let’s look at the common problems I see in openEHR implementation through that lens.
Every week I get asked some variation of:
These aren’t edge cases, they are normal developer workflows.
When integrating healthcare data into standard tech stacks is unusually hard, it is a platform problem.
Templates evolve and archetypes can have new versions introduced. But what happens to your historical data?
We’ve had a real production incident where pulse.v1 was used instead of pulse.v2. Our queries only looked for v2. The result? Missing clinical information.
This isn’t a modeling problem. It’s a maintainability issue.
Outside healthcare the technology frontier is accelerating. New tech is introduced everyday. A developer today likely uses AI-assisted coding, GraphQL, massive analytics engines or BI tooling.
openEHR and FHIR tooling is also growing, but much slower.
And there’s the uncomfortable reality. Healthcare runs on 1-3% margins. It cannot sustain massive custom infrastructure indefinitely.
If we keep building highly specialized tooling while the broader ecosystem moves faster, we widen the gap every year.
Let’s get precise. A data platform must be:
Reliability means that the system is resilient to data anomalies and concurrency issues.
Here’s a quick example of an update anomaly:
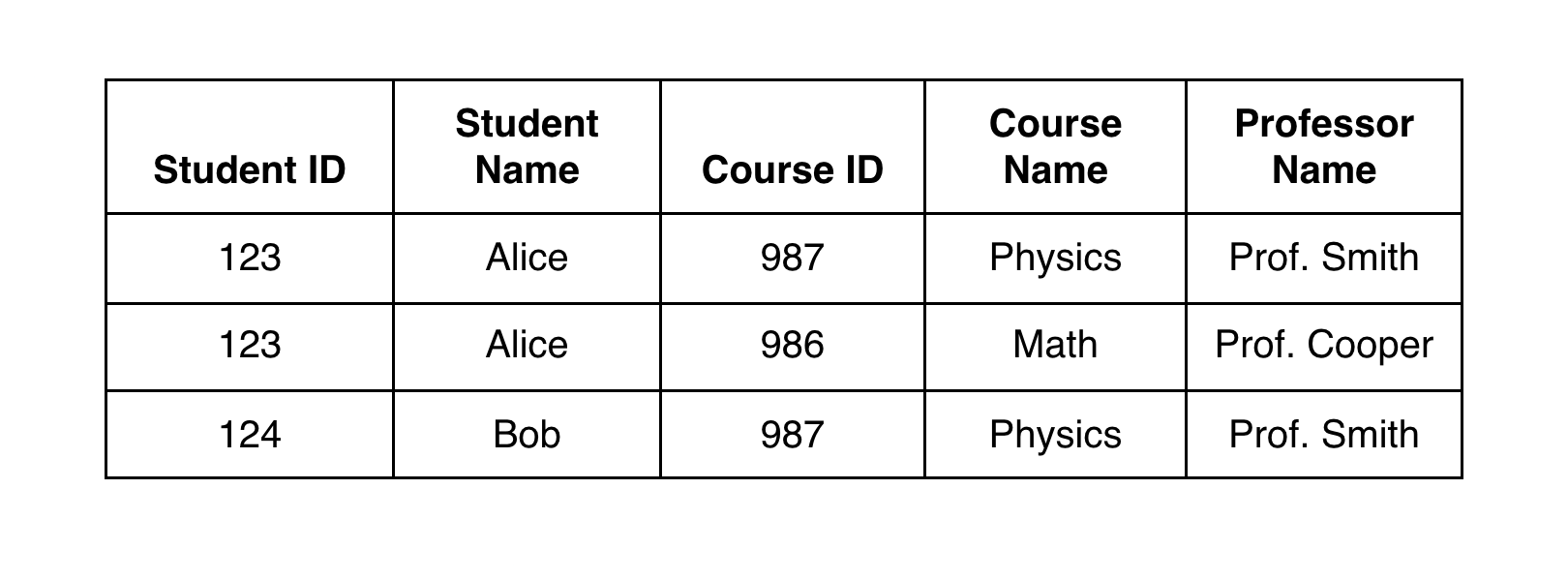 If ‘Prof. Smith’ needs to be replaced with ‘Prof. Johnson’ the update needs to be made in multiple places. If one record is missed, the meaning is corrupted.
If ‘Prof. Smith’ needs to be replaced with ‘Prof. Johnson’ the update needs to be made in multiple places. If one record is missed, the meaning is corrupted.
That’s why relational modelling pushes you to normalize and include foreign keys, to ensure consistency.
Transaction anomalies are trickier to solve. For example, in a scheduling workflow, two people book the same doctor at the same time. If the system doesn’t enforce proper transaction semantics, you can end up with a double booking (or a write skew). There are many types of transaction anomalies including phantom reads and read skews. They often go unnoticed until something breaks in production.
This is also why a REST API by itself is not a data platform.
Relational databases have solved transactional integrity problems for decades. If your architecture is relying on application-layer logic to guarantee correctness, you’re already in dangerous territory.
Healthcare data grows fast.
In many openEHR and FHIR implementations, JSONB in PostgreSQL is used to store compositions and resources. It works well, until it doesn’t.
At around ~3 million records, we hit performance cliffs. We know what happens next. Teams try throwing more compute at the problem and hope the cliff moves.

But having scalability in real data platforms isn’t just about “Can it run?”, but how cost grows as volume grows. Healthcare cannot afford exponential infrastructure cost curves.
Data must evolve cleanly. This is often ignored.
The practical question here is: when your model changes, how do you migrate so there’s still one source of truth?
Relational databases have solved this with schema migration methods, declarative database management and CI/CD pipelines for database schemas.
In many healthcare stacks however, model evolution is operationally expensive and error-prone
There’s also the very practical constraint of operability. Most healthcare systems don’t need kilometre-long cloud architectures to function. When more stateful services are introduced, it becomes harder to back up, patch, update and debug. Simple systems are easier to run. Easier systems survive longer.
SQL is also the benchmark most teams already run in production.
So, the question isn’t “Can SQL work for healthcare?”
It is: “If SQL meets the bar for most industries, why do we treat healthcare data as a special case?”
The relational model was built to meet these three criteria of scalability, reliability and maintainability.
Michael Stonebraker’s famous papers, What Goes Around Comes Around and What Goes Around Comes Around… and Around evaluate decades of database innovation and repeatedly arrive at the same conclusion.


The relational model keeps winning.
And here’s where things get interesting. openEHR was designed nearly 20 years ago. And relational database tech has evolved significantly since then.
Back then databases were less capable. Tooling was limited. Schema evolution was harder. Deep security at the DB level was not possible.
But today, PostgreSQL’s wire protocol has expanded interoperability dramatically. Tools like Supabase and PostgREST, and platforms like Hasura can generate REST APIs directly from database schemas.
Analytics has moved forward with Apache Iceberg enabling vendor-neutral analytical table formats and DuckDB allowing serious analytical queries to be executed locally with surprising speed.
And importantly, security has evolved. Row Level Security (RLS) allows deep, declarative access control directly in SQL. So, permissions are enforced at the data layer, not just in applications. This matters even more now because it’s not just humans using apps, AI tools and agents are also interacting with systems on behalf of users. The more security is enforced at the database layer, the safer and simpler the system becomes.
This changes the game.
We may no longer need separate transactional and analytics systems, custom terminology servers and heavy abstraction layers for every interaction.
Here’s my controversial idea:
What if openEHR definitions were modelled directly as SQL tables?
Today many implementations route everything through a CDR abstraction, persist complex JSON structures and depend on sophisticated query layers to reconstruct meaning.
Instead, let the database do what it does best. Define a strong relational schema. Enforce integrity through foreign keys and constraints. Apply security declaratively through RLS. Generate APIs directly.
With the tech we had 20 years ago, abstractions for openEHR were layered on top of the database.
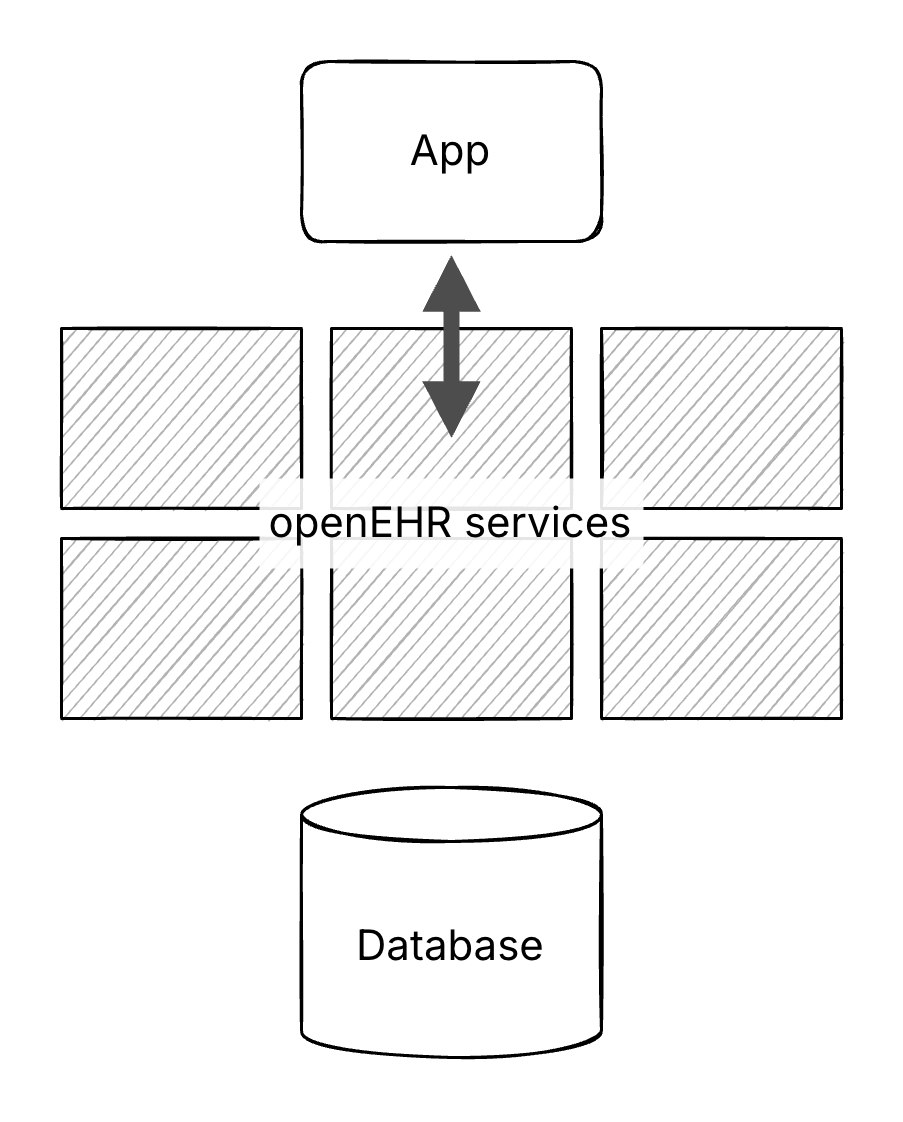
Now, we can lean into the database as the core platform.
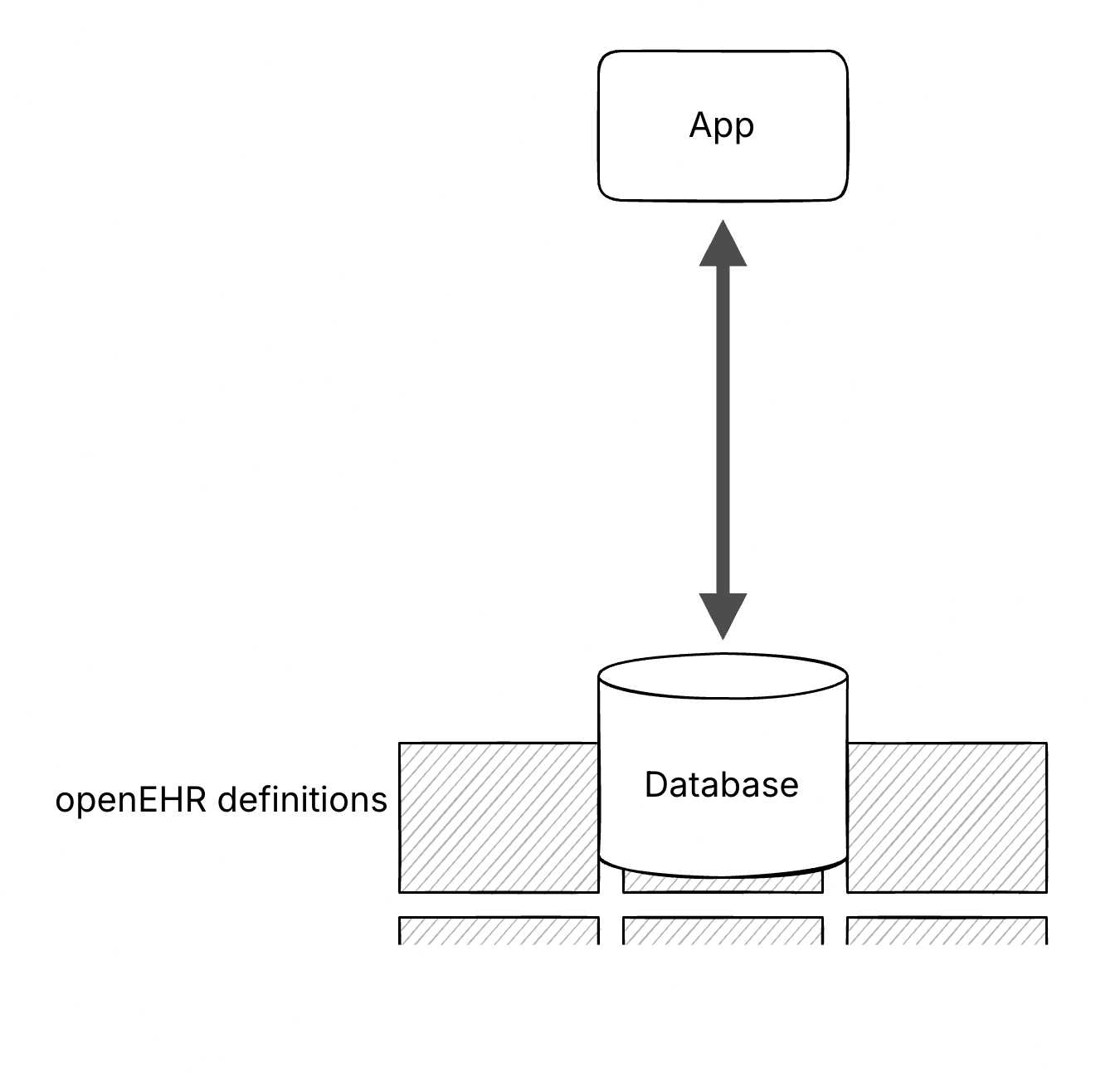
By moving these definitions, including archetypes, templates and RM classes, to the database level, the architecture could be simpler. It aligns better with the scalability, reliability and maintainability expected from a data platform.
Best of all? Once it is SQL, the integration becomes boring in the best way. BI tools integrate better. AI-assisted coding can plug in. Talent can be scaled easily (this is something we have struggled with too).
We’ve prototyped this. Modelled CKM data types into relational tables. Implemented terminology validation using foreign keys. Handled one-to-many and many-to-many relationships using standard normalization. And most AQL queries we tested can be easily expressed in SQL.
This has been the strongest criticism.
openEHR has always had its strengths, maximal modelling and two-level modelling. The concern is that moving to SQL would reduce semantic sophistication.
That’s fair. But that brings us to the trade-off.
Giving up 5% semantic expressiveness can bring 10x tooling, 100x developer availability and massive cost reduction. Is that compromise worth exploring?
It’s not about discarding openEHR, but rethinking where abstractions live.
The goal is simple: get healthcare back onto the standard developer stack, so we stop rebuilding tools. I worry that we are paying a huge complexity tax to preserve meaning.
Modern SQL databases already give us reliability, scalability and maintainability as defaults. The ecosystem around them is moving faster than any healthcare-specific stack can.
If we align with this ecosystem, we get to ride 50 years of database progress, instead of recreating it.
The question isn’t whether SQL is perfect. It is whether the trade-off is worth it.
I’ve covered the main argument here, but the live Q&A and debate adds important nuance. Watch it here:
Why openEHR works better as a silver layer in your data warehouse than as a CDR, and what that means for clinical data at scale.

While open standards set the rules, open source gets the work done. Discuss choosing tools, handling semantics and making health systems interoperable.

Health IT has various standards, and choosing the right one is often confusing. Understand the differences clearly to select the right standard.
No comments yet. Be the first to comment!
