
The Data Warehouse is openEHR's Strongest Use Case Right Now
Why openEHR works better as a silver layer in your data warehouse than as a CDR, and what that means for clinical data at scale.
February 4, 2026
If you worked with us this year, there’s a good chance we let you down.
Between January and September 2025, we outsourced over half of our service engagements to service partners. We thought it was a smart way to scale.
It wasn’t. And some of you had to deal with work that never should have shipped.
This is a breakdown of what really happened, how we’re making up for it, and what we’re doing differently.
Let me back up.
Medblocks started as a bootstrapped company. No investors. No pressure to hit arbitrary growth targets. Just a small team doing healthcare interoperability work for clients who needed it.
Early on, I turned down a $1 million offer because I didn’t yet understand what we were building or how we’d really deliver value. That decision bought us time to figure out the problem properly.
It also set the tone: we’d rather say no than sell something we didn’t believe in.
Our first team members weren’t hired through job postings. They found us.
Poornachandra, a doctor who taught himself to code, reached out after seeing my GitHub work on medblocks-ui. He’s now our CTO. Vipin had built a Dental EHR with thousands of users and joined our FHIR Bootcamp because the data in his EHR was a mess. Aditya was building Voice-to-Notes for his ophthalmologist parents when he found my videos.

None of them came through a recruiting pipeline. They came because they already cared about the problem.
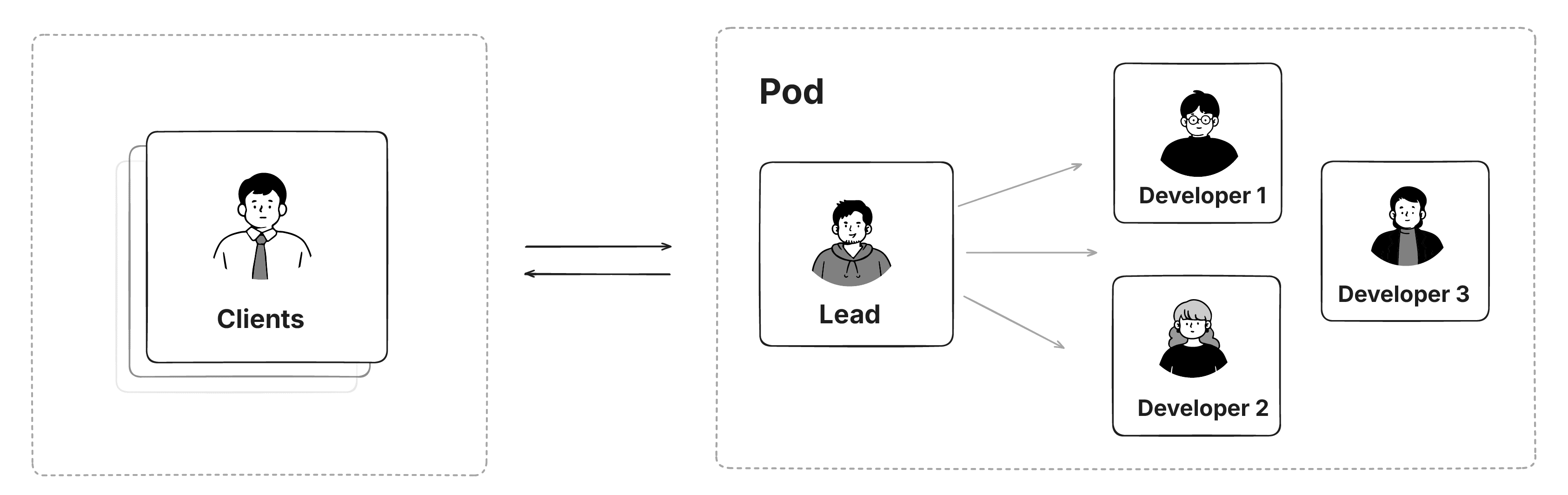
As we took on more projects, we recruited additional developers. But the team leads were always one of these three. They understood the domain, knew how to ship, and cared about getting it right.
This became our Sprint model: a dedicated team of 3 working closely with customers on complex healthcare projects. Custom EHRs. Oncology clinical decision support. Spain’s Federated Data Platform. Real problems, shipped.
We didn’t just build what we were hired for. We questioned the “why” behind every feature. What’s the actual workflow? Who’s using this and when? What problem are we really solving? Sometimes the answer changed the entire approach. That’s what happens when your team understands the domain deeply enough to push back.
Customers loved working with us. Projects were delivered on time. Teams stayed on engagements long enough to understand the client’s systems inside out.
Then things changed.
We always wanted to stay lean. As a bootstrapped company, you get used to the cloud computing mindset: scale up when you need it, scale down when you don’t. Resources on demand.
In 2025, we got more business than all previous years of Medblocks combined. Revenue jumped by over $1M. Great problem to have, right?
Except we only had three team leads. And me, who they consulted extensively for niche problems. That’s it. Four people who could actually lead projects and make decisions. We couldn’t just magically get more of us.
We could hire developers under a pod lead, sure. But the pod leads themselves? Almost all of them found us. We didn’t know how to recruit people like that.
So we did what seemed logical: partner with other service companies. Share revenue. Let them handle the delivery while we provide oversight and domain expertise. Scale horizontally through partnerships instead of hiring.
We weren’t naive about this. We looked specifically for service partners in Health IT with track records of delivering to large customers. We interviewed their team members. Put them through our training and processes. Set up a transparent revenue-sharing model where they got the majority of the revenue.
On paper, it made sense. In practice, everything broke.
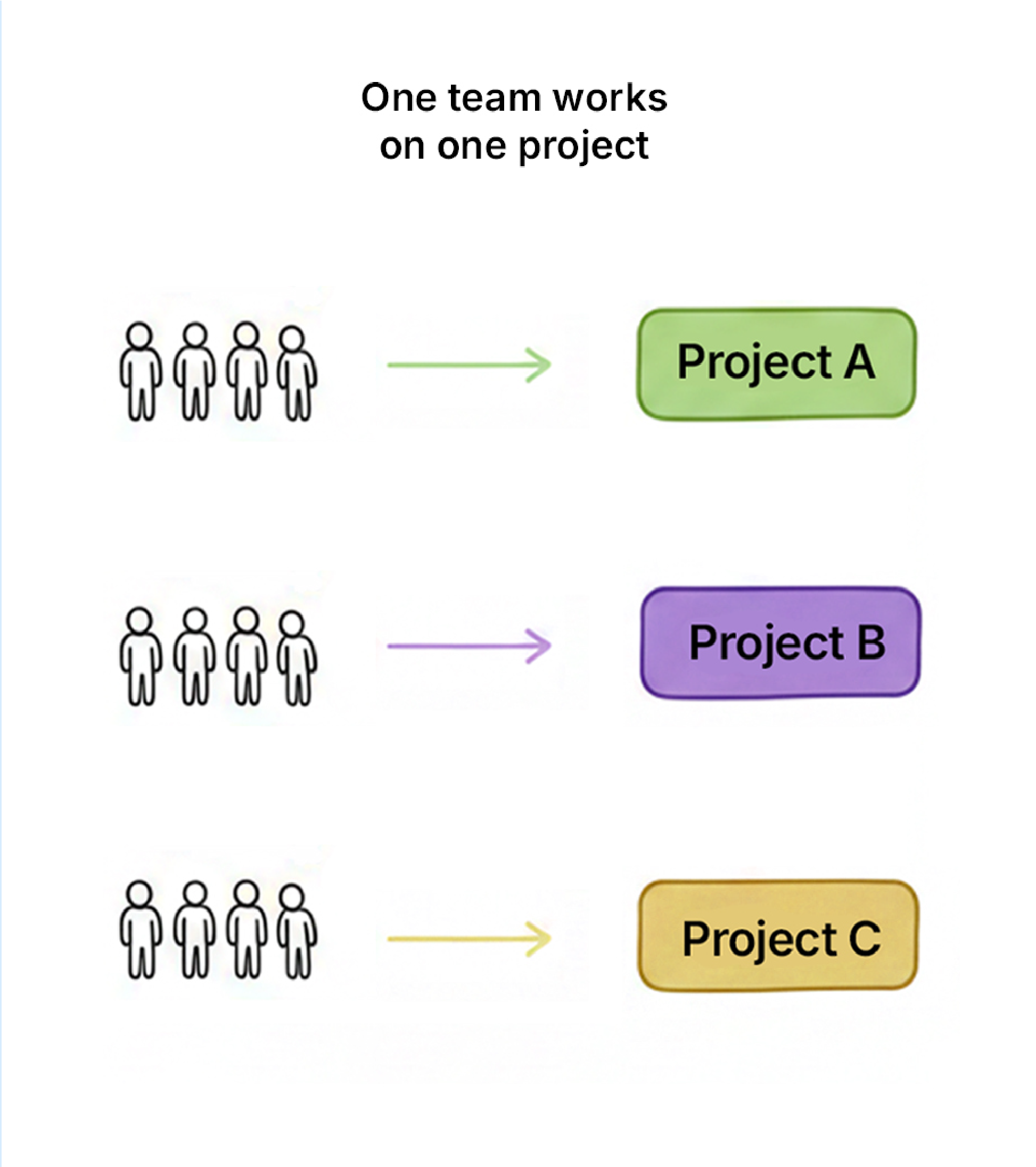
Our teams work on one major project at a time. That’s it. One project, full attention.
This isn’t just about focus. Teams need time to form. There’s a reason Tuckman’s model exists: forming, storming, norming, performing. You can’t skip the stages. Our teams had been working together for years. They knew each other’s strengths. They had the brain space to think deeply about problems, not just execute tickets.
There’s a concept in Team Topologies (which I highly recommend reading) called flow-aligned teams. The idea is that teams should be structured to minimize handoffs and context switching. Everything the team needs to deliver should be within the team. We get dependencies resolved upfront. We don’t have “waiting time” on other teams.
Our service partners promised us “dedicated” teams. But something felt off.
They were always waiting on something. Waiting on credentials. Waiting on approvals. Waiting on the client to respond. Projects kept stalling.
Here’s an example: deployments. Our teams deploy to production themselves. Before a project starts, we require clients to give us access and assign facilitating team members on their side. We resolve these dependencies upfront so there’s no waiting later.
Conway’s Law says organizations design systems that mirror their communication structures. If your team has to wait on three other teams to deploy, your architecture will have three unnecessary integration points. If your team owns the full pipeline, you ship faster and simpler.
Our service partners didn’t set any of this up. They just allocated people. Didn’t ask for production access. Didn’t request facilitators from the client. They didn’t ask the right questions upfront. Didn’t get the right people involved early. No flow alignment.
Weeks into projects, they’d hit walls. “We’re waiting on approvals. Everything is on track. The team is fully allocated.”
We started to suspect what was actually happening. The teams were likely overbooked on other projects. Dependencies weren’t real blockers. They were cover. While we thought they were waiting on a credential, they were probably working on someone else’s project.
And it seemed like this was by design. Stack up enough dependencies and the customer never finds out you’re overbooked. “We’re just waiting on an approval. Everything is on track. The team is fully allocated.”
When something breaks in production for one of our customers, we’re up at night debugging. We’ve had long-term relationships with most of our clients. If they’re down, we feel it. We take it personally.
That changes how you build. We put in effort upfront: pair programming, code reviews, monthly meetings where the team discusses what they learned, and footguns to avoid. We ship carefully because we know we’ll be the ones fixing it at 2 am if something goes wrong.
Our pricing model aligns with this: customers pay a fixed monthly fee to hire a team. Everything is included. We don’t charge extra for bug fixes. We don’t charge extra for incident support. It’s in our interest to ship clean code the first time.
Our service partners had the same fixed-fee arrangement with us. But their habits came from years of inflated hourly billing. Their processes were built around it. Don’t clarify scope upfront. Skip the architectural thinking. Build fast, fix later, bill more for it.
A friend of mine who works at one of the biggest service firms in India told me something that stuck with me: they sometimes intentionally ignore deep architectural issues early on because it leads to more rework later.
That IS their business model.
Everyone at Medblocks cares about the domain. We know how shipping buggy code could affect patients. How a well-designed system might actually improve someone’s life. That’s in the back of our heads every time we build something.
We tried to get the service partner teams up to speed. Put them through our training bootcamps. Shared our processes.
It didn’t stick.
Their PMs were “in” healthcare, not of it. They didn’t understand the tradeoff between free-text entry and structured form fields to an end user. To them, FHIR, openEHR, SNOMED CT, and OMOP were just “data standards” - interchangeable acronyms. They didn’t see how choosing the wrong one could lock a client into years of technical debt.
Some of their developers had domain knowledge from previous projects. But the teams were so unstable that expertise never accumulated. New person joins, learns a bit, moves to different projects, and leaves. Repeat.
We thought we’d at least be useful for consultation. When they hit tricky architectural decisions, they’d loop us in. That’s what we were there for.
They never did. Just close your eyes and build.
And AI makes this worse. Before, when you didn’t understand something, you had to ask a person. That meant admitting you didn’t know. Now you just prompt the AI. It gives you a confident answer. You build that. No clarification. No questioning. Just code that technically runs but misses the point entirely.
It all comes back to hiring.
We didn’t expand our own teams because we didn’t know how to hire team leads. We still don’t. Poorna, Vipin, and Aditya all found us. We don’t have a repeatable process for finding people like them.
But even for developers under a team lead, our hiring process is brutal. We follow The A Method religiously. Initial screening. Coding round with a senior developer. Final round with me where I go through every significant job they’ve had, ask about their bosses, their low points, why they left. Then reference checks with their previous managers. Not the references they provide - the actual bosses they mentioned during the interview.
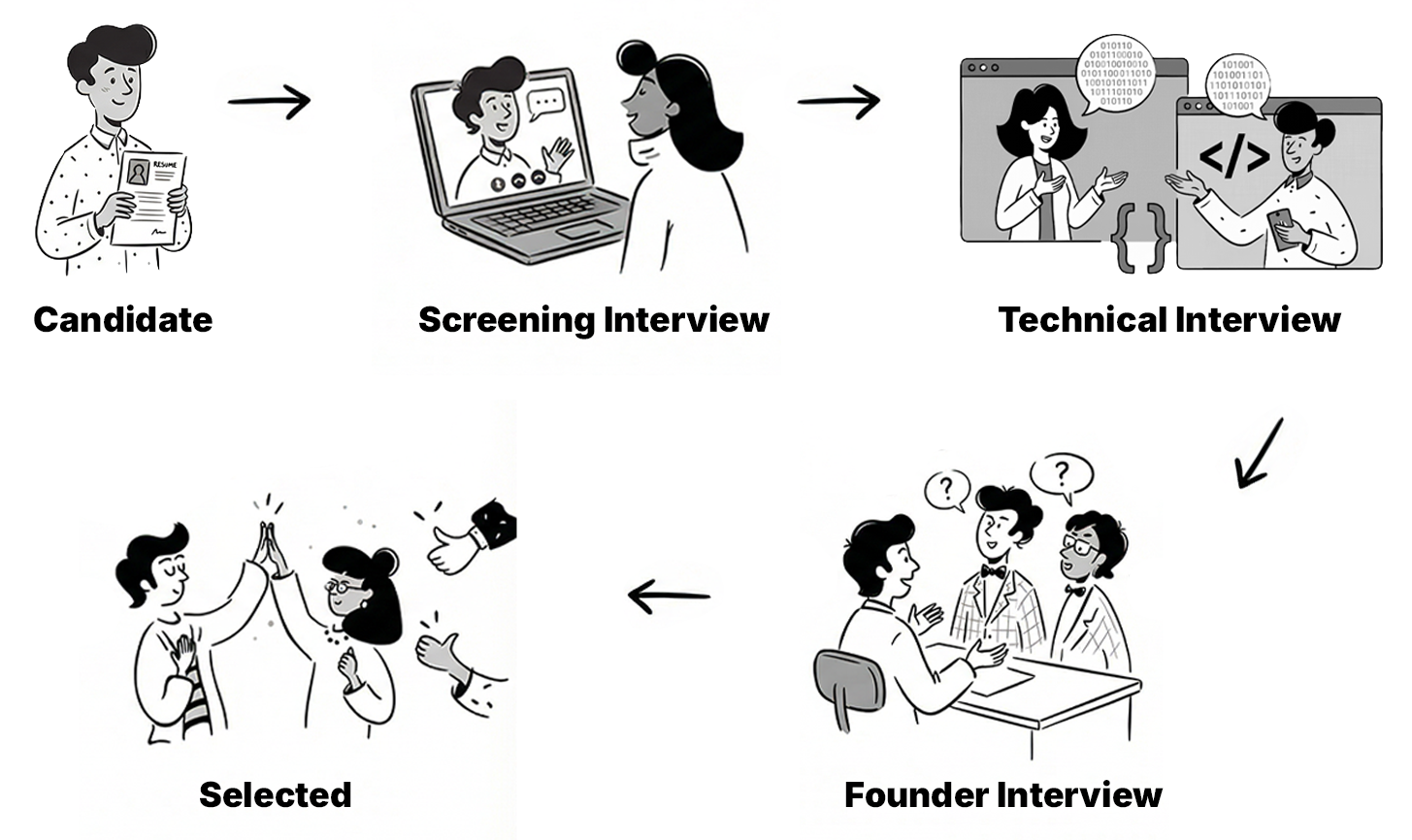
The whole process takes at least 2 months for a single hire. Our rejection rate is 94%.
Our service partners could staff a project in 2-3 business days.
How? No reference checks. Minimal vetting. Bring in anyone who could “code”.
The difference showed immediately. Communication wasn’t as sharp. Technical depth wasn’t there. And the attrition was insane.
In Medblocks’ entire history, we’ve had 2 people leave. Two. Both left to pursue higher studies.
Working with service partners for just 2 months, we saw more than 5 people rotate off projects. New faces every few weeks. No continuity. No accumulated knowledge. Every handoff meant re-explaining context from scratch.
Many of them seemed burnt out. Juggling multiple projects, constantly context-switching, never getting deep into any one problem.
We’d put these people through our bootcamps. Interviewed them. Onboarded them. And then they’d leave to join another company offering a slightly better salary.
I think I know why. Most of them were being paid as little as possible so the service partner could retain margins. Low salary, low loyalty.
We pay all our employees well above market rate. Sometimes we even offer people more than they ask for to accommodate their growth in the organization. Our philosophy: one great hire at 2-3x the salary is 10x better than three mediocre hires on low salaries. Our service partners clearly didn’t believe in that.
If you were affected by this, you probably already know. And our team is probably already working on it.
We’re doing everything we can to fix the damage. Offering additional work free of cost. Rewriting code that should never have shipped. Getting things to where they should have been from the start.
The math is brutal. For every unit of effort our service partners put in, we’re now putting in 2-3x to fix it. And we still have to pay our service partners for their sloppy work. So we’re effectively running at 3-4x the cost of just having done it ourselves.
We’re bleeding money. But we made a promise when you signed up with us, and we’re going to keep it. This is on us, and we’re going to fix it.
We’re only accepting projects that our own teams can deliver. No more service partners. No more shortcuts.
We’re expanding to the US this year. But expansion without the right people is just a recipe for repeating the same mistakes. So we’re building the foundation first.
The problem: we still don’t have any new pod leads. Zero. We’re actively looking, but as I said earlier, we don’t really know how to hire for this. All our current pod leads found us. And we have a really high bar to hire new ones. We got lucky. We need to get lucky again.
This means we’ll be taking fewer projects this year. Revenue will likely drop back to where we were before the growth. We could technically chase revenue, use more service partners, ramp up sales to compensate for churn. That’s what a lot of venture-backed companies do. But we’ve never raised money, and we plan to keep it that way. That gives us the freedom to say no.
So we’ll be saying no a lot this year. It’s hard. But we want to do this right.
When we do say yes, we’ll deliver at the quality our long-term customers have come to expect.
Slow growth. Trust over revenue.
We’ll also be more transparent about which teams are available, who’s on them, and what their experience is.
If you want to work with us, reach out 1-2 months before you need us. We book projects in advance and require an advance payment to reserve a team. It’s the only way we can make the math work while keeping teams dedicated and not overbooked.
Hiring is our bottleneck. Developers are abundant. Good ones are rare. People who can lead projects, understand the healthcare domain, and actually care? Even rarer.
If you know someone like that, or if you’re reading this and thinking “that sounds like me,” please reach out. We’re hiring in India and the US. Remote-first. Competitive salaries (well above market, as I mentioned). Meaningful work that has a direct impact on people’s lives.
Write to me directly: sidharth@medblocks.com. Tell me your story. I read every application personally.
If we let you down this year, I’m sorry. We’re doing everything we can to make it right. And we’re building the team so that as we grow, we can deliver more of what you’ve come to expect from us.
Thank you for sticking with us.
Why openEHR works better as a silver layer in your data warehouse than as a CDR, and what that means for clinical data at scale.
My mother-in-law needed a clinical trial. My wife and I, both doctors, had a hard time finding the right one. I decided to try to solve it.

I make the case that SQL could be the solution to simplifying the layers of complexity in health data architecture. This is a written version of my talk at EHRCON 25.
No comments yet. Be the first to comment!
