

Can openEHR just be SQL tables?
I make the case that SQL could be the solution to simplifying the layers of complexity in health data architecture. This is a written version of my talk at EHRCON 25.
June 11, 2026
Nobody is ripping out Epic to install openEHR. I’ve made peace with that. But that doesn’t mean openEHR lost.
openEHR was built to unify clinical data at the application layer. Define your clinical models once using archetypes, store everything in a Clinical Data Repository (CDR), and have every application read and write to the same store using standard APIs.
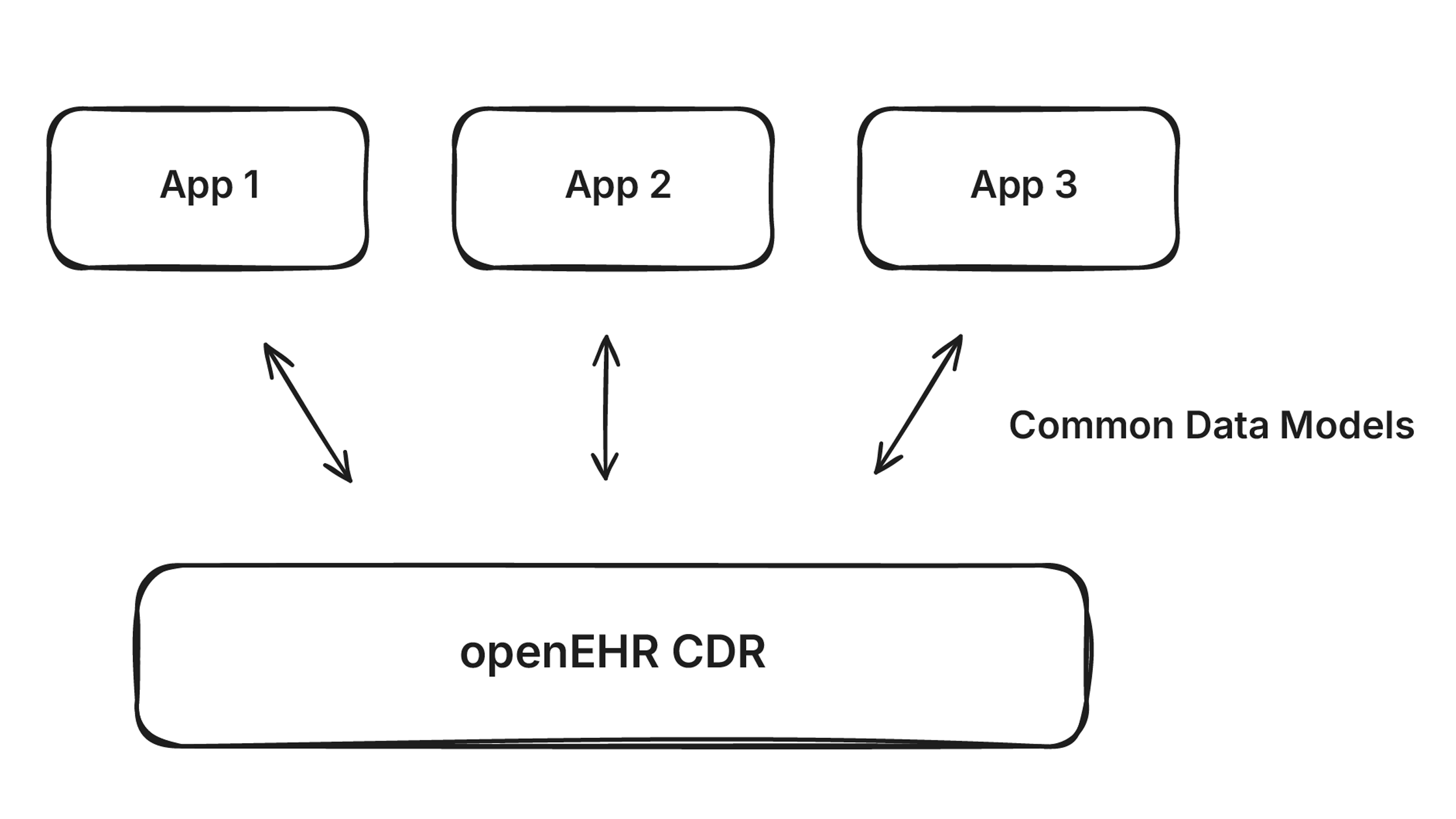
It’s an elegant idea. It’s also not how most of the world works.
What is happening is messier. Organizations buy EHRs and point solutions, each with its own data model. The data fragments across dozens of systems. openEHR was supposed to prevent this, but it hasn’t played out that way.
In this article, I want to make the case that openEHR’s most valuable contribution isn’t the CDR. It’s the clinical models. And there might be a better place for them.
When a health system is evaluating what to buy, they’re comparing an openEHR CDR where you build your own configuration against an EHR that handles everything out of the box. openEHR today covers clinical data modeling. It doesn’t do billing, scheduling, or administrative workflows. Even with low-code tools or vibe-coded AI apps, organizations can’t deploy clinical applications at scale because they can’t agree on the workflows. Two doctors will have different ways of doing the same thing.
What systems like Epic actually provide is decades of workflow modeling and a workforce that has learned to accept those workflows as a shared compromise. Brendan Keeler’s There Will Be Bundling is a great read on why this kind of enterprise software naturally consolidates into bundled systems of record. Switching costs are enormous, data gravity keeps everything in place, and the buyer wants one system that does it all.
Charité, Germany’s largest university hospital, chose Epic even though they already had openEHR in their organization. They were heavily involved in the openEHR movement and community, and picked a bundled solution anyway. And once these systems are in place, they’re nearly impossible to remove. Decades of implementation, generations of trained workforce, and every other system in the organization depends on them.
The idea behind a separate CDR is still valuable. A vendor-neutral store for clinical data that you own and control, independent of any EHR. Patients are generating more data than ever through wearables, wellness apps, and social determinants of health. EHRs weren’t built to store all of this. A flexible, open CDR that can capture what the EHR can’t is a compelling vision, and a lot of smart people believe in it.
But those same people have had to come to grips with reality. The EHR is going nowhere. So in practice, openEHR gets implemented as the integration layer. Data gets copied from existing systems into a CDR, so the organization always has control of its own data.
But hold on. Aggregating data from multiple systems into a central store? That’s exactly what the data warehouse already does in many organizations.
Quick note on terminology: I use “data warehouse” loosely throughout this article. A data warehouse stores structured, transformed data optimized for queries. A data lake stores raw data in any format cheaply at scale. A lakehouse combines both, letting you query raw and structured data in one place. Whether you’re running any of these, the argument applies the same way. If your organization has a central place where clinical data from multiple systems lands for analytics and secondary use, that’s what I’m talking about.
If a data warehouse aggregates data from multiple systems for analytics, are openEHR CDRs doing the same thing, but worse? I think so. The CDR is a transactional system (OLTP). The data warehouse is an analytical system (OLAP). As Stonebraker et al. argued in “One Size Fits All: An Idea Whose Time Has Come and Gone”, no single system can do both well.
The difference is in how each system stores data on disk. A transactional system stores data in rows, with each piece of information for a single patient, (name, age, etc.) stored next to each other. When an application wants to retrieve data related to one specific patient, it goes to the appropriate row and finds the requested information.
On the other hand, an analytical system stores data in columns. All records for all patients are broken out into separate categories based on the type of data being analyzed. E.g., patient age together, and diagnosis codes together. This makes it easier to handle population level questions like, what is the average age of patients with hypertension in my dataset? A row-based system would scan every single row to answer that, touching every field for every patient even though it only needs two columns. A column-based system goes directly to those columns and skips everything else. A query that takes minutes on a transactional database runs in milliseconds on a columnar warehouse.
This is why an openEHR CDR struggles as an integration layer. It was built for reading one patient at a time and not large analytic queries The warehouse was built for analytical efficiency. Organizations are already pouring data from every system into Snowflake, Databricks, Azure Fabric, and BigQuery. Storage is decoupled from compute, so terabytes of raw clinical data can be stored at almost nothing. You only pay when you query it.
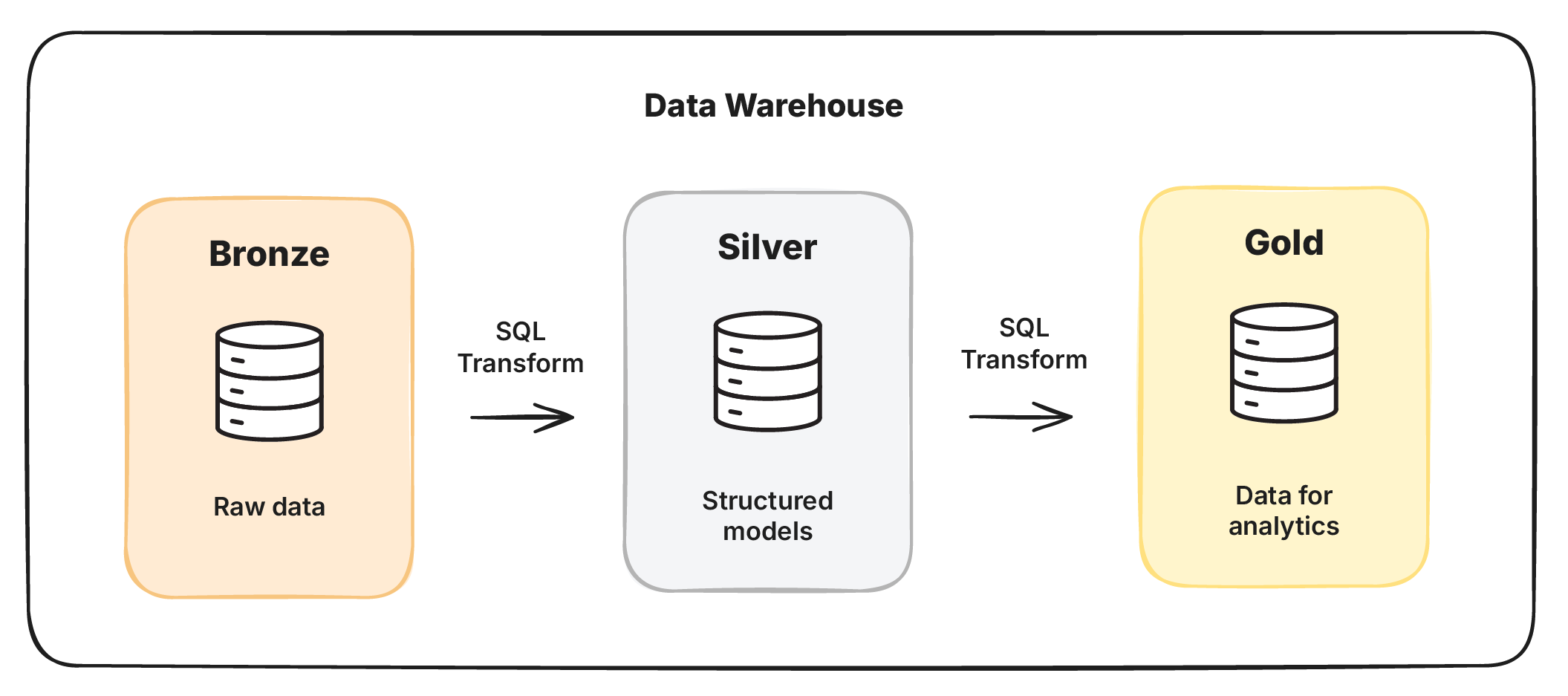
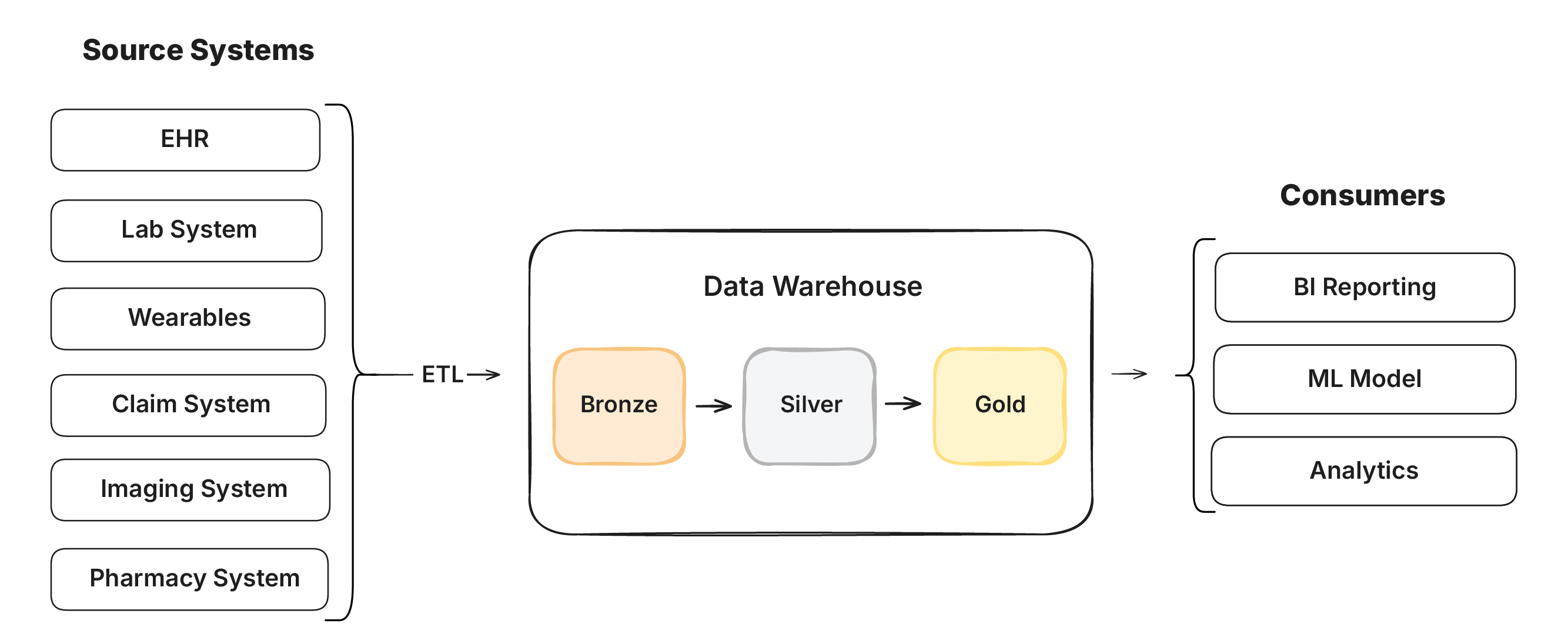
Instead of transforming data before loading it (ETL - Extract, Transform, Load), the warehouse flips this around. Load everything raw, and transform it inside (ELT - Extract, Load, Transform). The medallion architecture formalizes this: raw data lands in bronze, gets refined into structured models in silver, and shaped into use-case specific views in gold.
The data stays where it is. Each layer is just a SQL view or transform that reshapes the data. The raw data is transformed in place, on demand when a query is actually run.
| | CDR as warehouse | Data warehouse | | ----- | ----- | ----- | | Data pipeline | ETL | ELT | | Transformation logic | External scripts (Python, etc.) | SQL inside the warehouse | | Query language | AQL (non-standard across implementations) | SQL (LLMs, ML models, rich analytics) | | Template/model changes | No clear migration path | Versioned, testable, rerunnable transforms | | Data storage | Physical copy of data transformed to match archetypes before loading | Raw data stored once, transformed in place via SQL | | Cost model | Pay for all patients, all data stored | Pay per query, storage near-free | | Scalability | Compute and storage coupled | Compute and storage decoupled | | Tooling | Proprietary / openEHR-specific | Massive ecosystem (DBT, SQLMesh, etc.) | | Data lineage | Hard to track across ETL scripts | Built-in (DBT lineage, column-level tracking) | | Cloud support | Limited | Native in all major clouds | | Talent pool | Small pool of openEHR specialists | Millions of SQL/data engineers |
Compare this to getting data into a CDR. That’s ETL. Data is extracted from source systems, transformed to match the CDR’s templates, and then loaded. The transformation logic lives in (messy) Python scripts that need to change every time a template changes. There’s no clear way to migrate data from one template version to another. And if anything changes upstream, you have to rerun the entire pipeline.
In the warehouse, the transforms are written in SQL on raw data. SQL is arguably the most widely understood data language in the world, and tools like dbt and SQLMesh give you versioning, testing, and documentation out of the box. The transformation logic lives alongside the data, not in external scripts.
Could you do ELT inside the CDR instead? Not really. The CDR is a transactional store optimized for one patient at a time. The kind of complex columnar queries you need for views, materialized views, and incremental materializations are painfully slow on OLTP systems. And AQL can’t express them. No openEHR vendor supports views, incremental refreshes, or the kind of transform logic that warehouse SQL handles natively.
And the gap is getting wider. Modern warehouse SQL dialects can call LLMs, run ML models, and execute complex analytics natively. AQL will never keep up with this tech frontier. I’ve talked about this before in Can openEHR just be SQL Tables, in the context of having openEHR archetypes be SQL tables on transactional databases. The same argument about tooling, funding, and the widening tech gap applies even more strongly to the data warehouse.
A CDR also makes a full physical copy of every record from every source system. That’s expensive to maintain and creates yet another system that needs to stay in sync. If you’ve ever integrated systems in production, you know Murphy’s law applies. If two copies of data can go out of sync, they will. In the warehouse, structured models are materialized as views on top of the raw source data. There’s only one copy, nothing to sync, and you get full data lineage. You can trace any value in your warehouse model back to the exact source system and column it came from. Tools like dbt make this easy.
If this sounds like what Palantir’s Federated Data Platform does for the NHS, that’s because it is. Palantir aggregates data from multiple NHS systems into a unified platform with lineage and dashboards. It cost £480 million. Open-source tools like dbt, SQLMesh, DuckDB, and Trino now offer comparable capabilities. And with open table formats like Apache Iceberg, you can store your data once and have multiple warehouses across clouds query it. You don’t need to hand half a billion pounds to an ethically questionable company to build your data platform.
For the use case of aggregating all clinical data and having it ready to query for secondary use, the modern data warehouse stack is a much better fit. So if bundled EHRs own the system of record, and the data warehouse owns the integration layer, where does openEHR fit in?
openEHR’s real contribution was always the clinical archetypes: thousands of clinician-driven, peer-reviewed maximal data models that define what clinical data should look like.
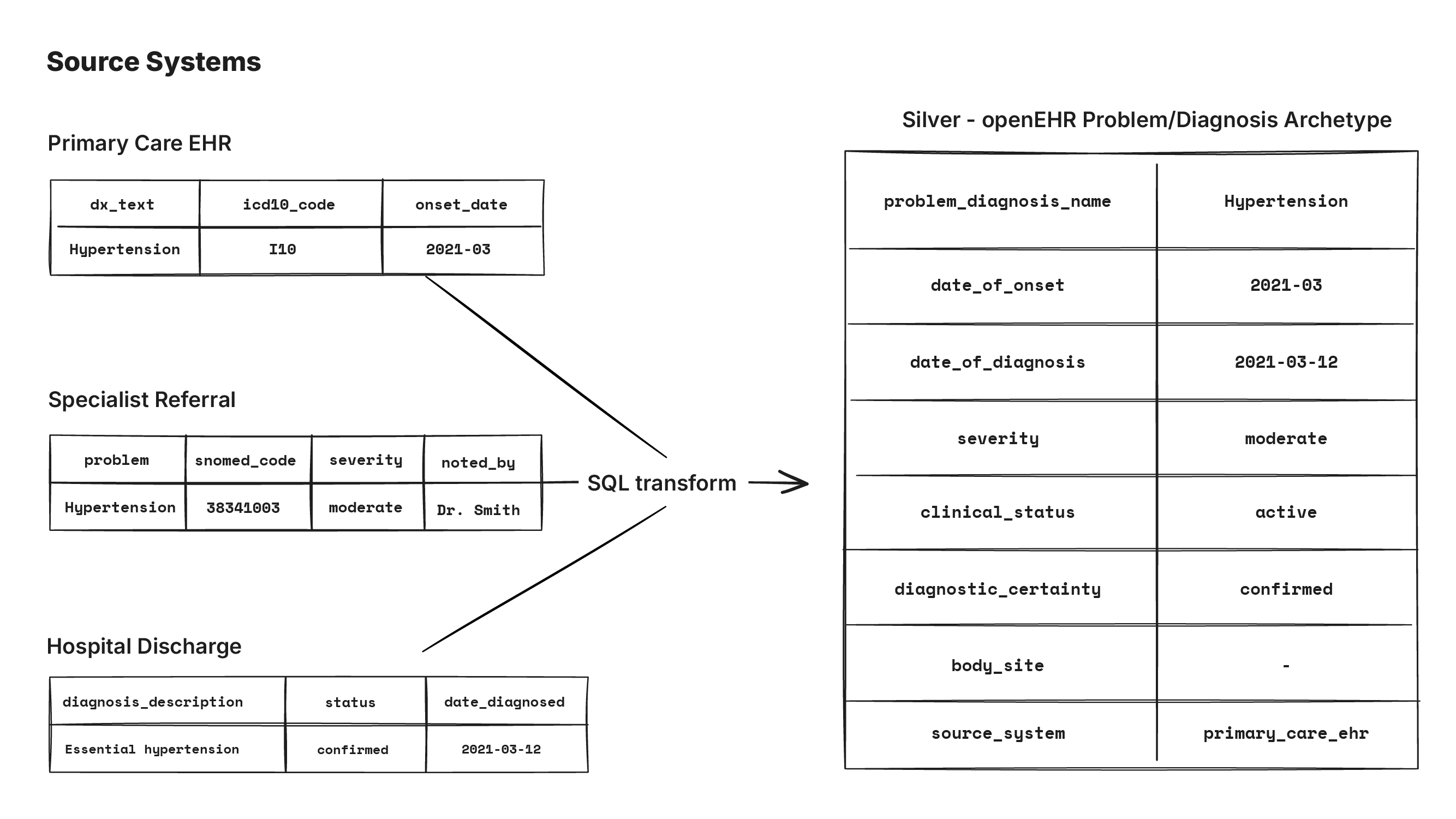
And raw clinical data in the warehouse is a mess. Even something as simple as tumor size can arrive from FHIR in hundreds of different representations depending on the source system. Without a shared semantic layer, every team writes their own mapping logic and you end up with ten slightly different interpretations of the same data.
openEHR archetypes solve this with maximal models that any team can derive their specific use case from. And this maps cleanly to the medallion architecture. Bronze holds raw data from source systems as-is. Silver is where openEHR archetypes live as SQL tables: the unified, maximal clinical models. Gold is where teams derive their use-case specific models from silver.
Take a problem/diagnosis as an example. It’s captured differently in a primary care system, a specialist referral, and a hospital discharge summary with different codes, structures, and levels of detail. In silver, all of these get mapped to a single problem/diagnosis table shaped by the openEHR archetype. Any team building a gold layer model for their use case will get to use this same foundation.
This is fundamentally different from how openEHR was originally meant to be used. In the traditional approach, you take a maximal archetype, constrain it into use-case specific templates, and build applications on those templates. In the warehouse, you have one global maximal archetype per clinical concept, and that forms the silver layer. There’s value in creating one representation for all use cases.
If the silver layer specification is clear on what the output model looks like, multiple teams can work on the mappings independently. The team working on Epic data can iterate on their bronze-to-silver transforms without coordinating with the team working on lab system data. As long as both produce a valid problem/diagnosis table that matches the archetype spec, it can be composed and merged trivially. This is exactly the pattern described in How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh: domain teams own their own data products, and the shared specification of the output is what makes it work.
And if there’s ever a governing push for standardized clinical data, this is far more practical than asking vendors to integrate with an openEHR CDR. Everyone knows SQL. Vendors already ship dbt packages that map their raw data to standardized models: Segment, Adwords, Aidbox, and dozens more. The Open Data Institute calls these data adaptors. There’s no reason openEHR archetypes as silver models can’t work the same way.
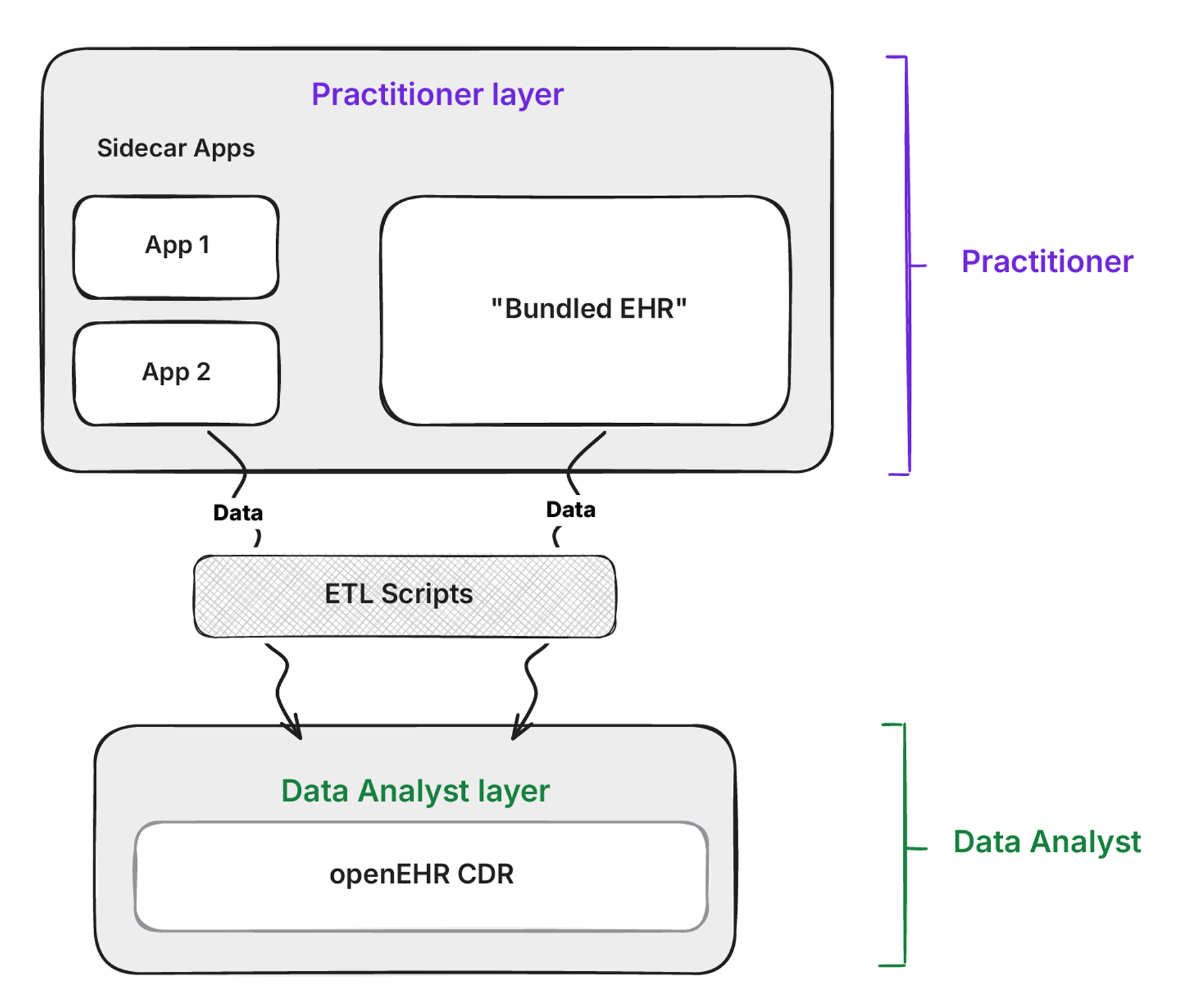
None of this means the CDR is useless. If you have an openEHR CDR, or an openEHR-inspired application built on something like Health Tables, it’s still a valuable source of data. It just becomes one more source feeding the warehouse, not the single source of truth for everything.
The CDR still has a role at the application layer. Applications built on the CDR, whether low-code, no-code, or vibe-coded, benefit from schema-on-write. The CDR enforces that data conforms to archetypes before it’s stored, so these apps can’t capture nonsense data. That’s valuable at the point of entry.
Data from the CDR then gets mapped to the openEHR silver models in the warehouse just like data from any other system. The difference is that because the CDR already speaks openEHR natively, the bronze-to-silver mapping is trivial compared to mapping from a proprietary EHR or a lab system. The warehouse is the analytical source of truth. The CDR remains the transactional system for the applications that use it.
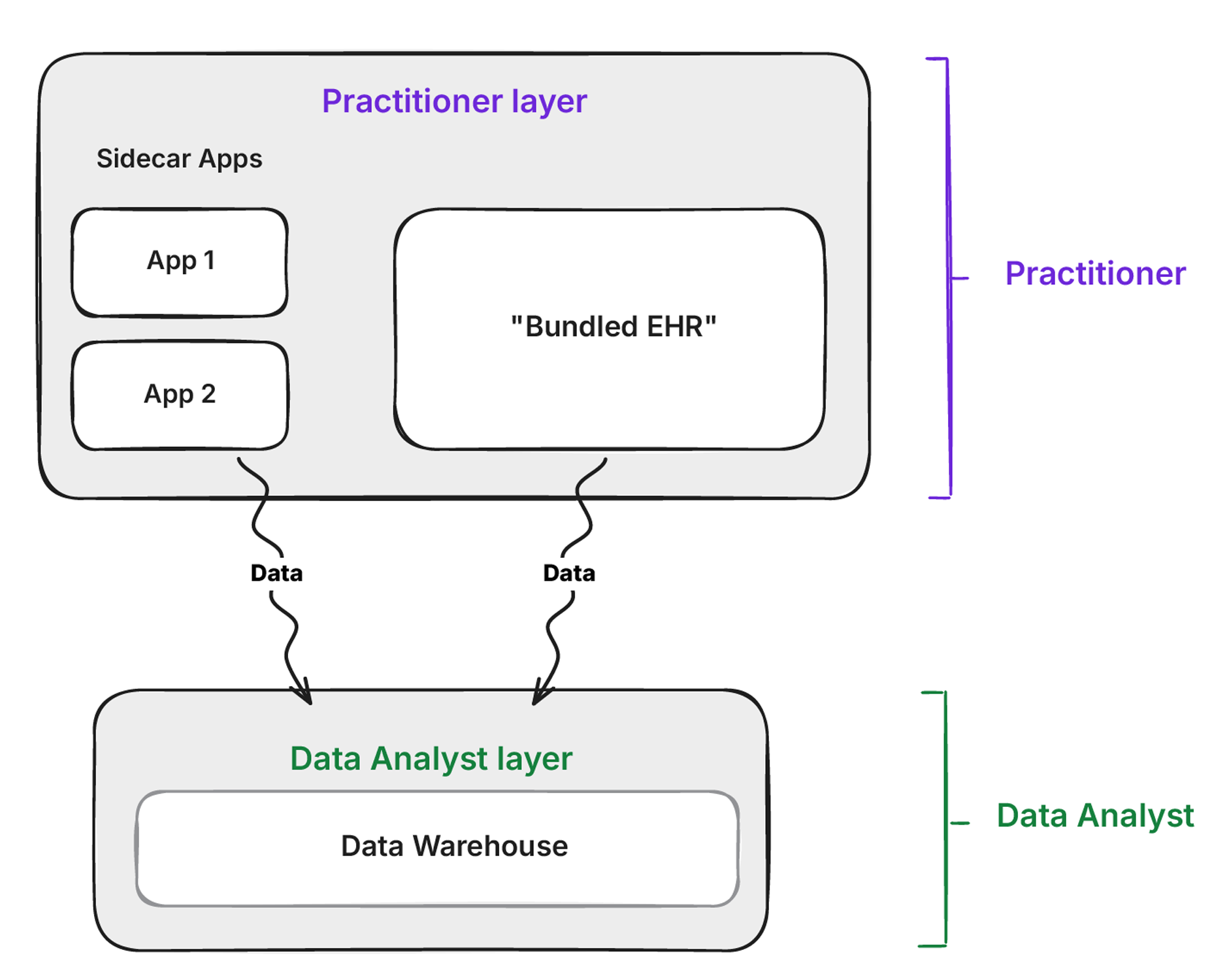
Should data in the warehouse be written back to the CDR? It depends. If you’re using the openEHR CDR as a shared care record or source of truth for clinical applications, then yes. Running transforms in the warehouse and writing the result back is more proven than ETL-ing data into the CDR directly from source systems. The main benefit is that integration from disparate systems happens once into the warehouse, and the transformation logic lives as versioned SQL alongside the data.
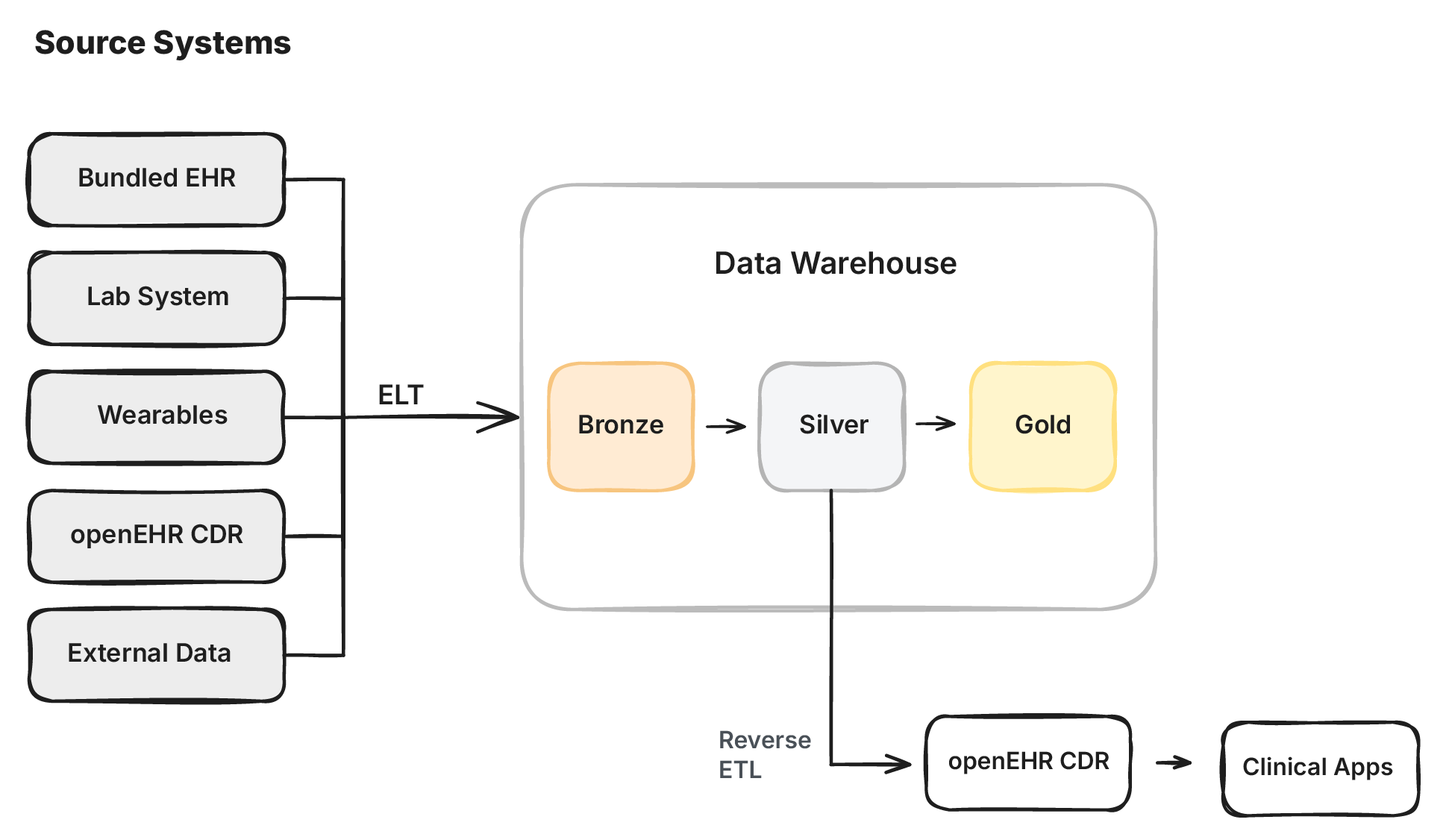
But once it’s in the CDR, it should be read-only. If people start editing it there, you have multiple sources of truth and you’re back to the sync problem.
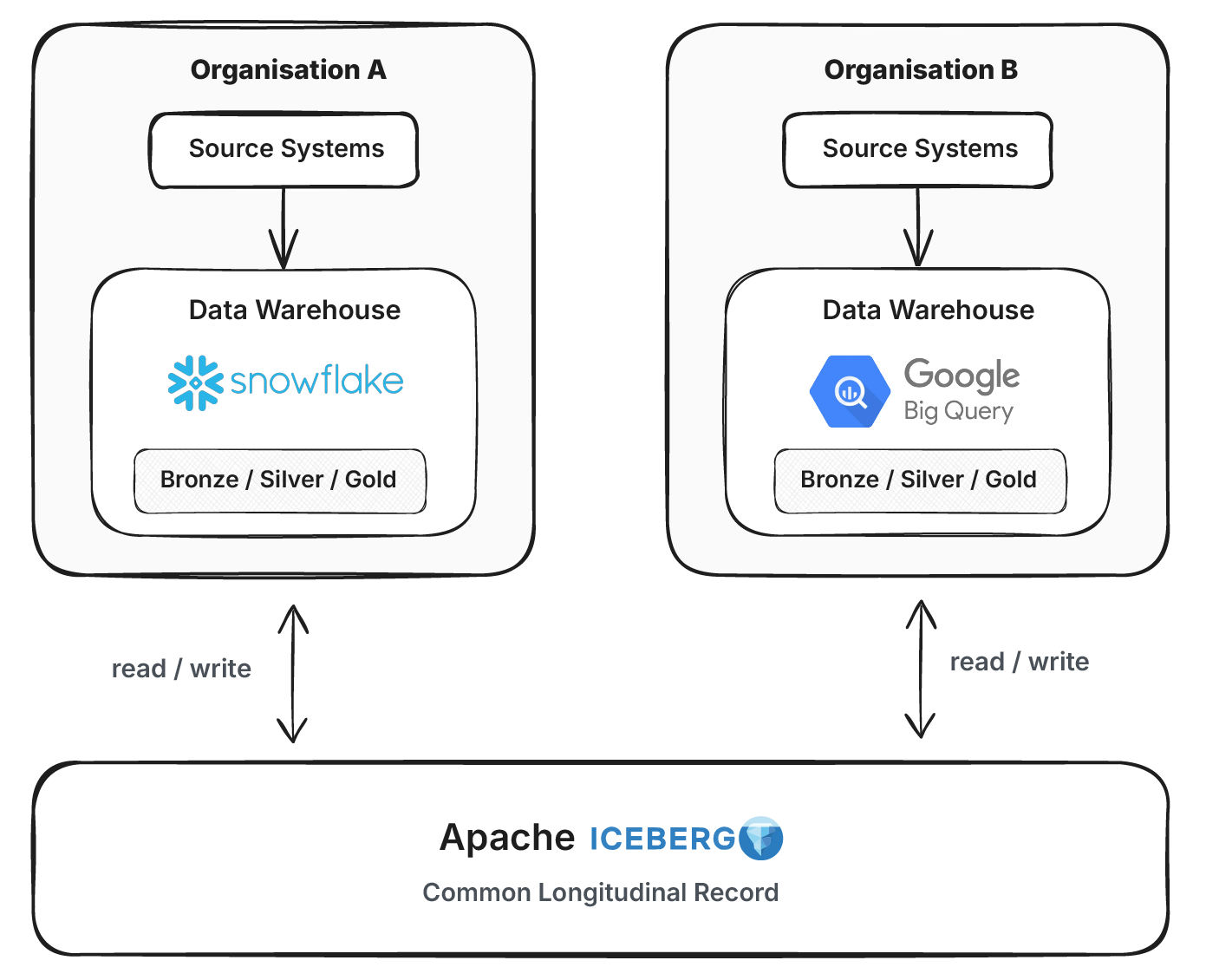
The other option is skipping the CDR entirely and using the warehouse as the shared record. With open table formats like Apache Iceberg and upcoming governance features like RBAC and unified logging via Polaris, multiple organizations can each run their own warehouse engine while sharing a common longitudinal record on a single Iceberg bucket. This deserves its own deep dive.
Before we get too excited, there are two foundational problems we need to talk about.
When data flows in from multiple systems, duplicates are inevitable. Duplicate patients, duplicate encounters, duplicate observations. Unified openEHR silver models only work if you know which records belong to the same patient. Getting that right across disparate systems with different patient identifiers, different data quality and different levels of completeness is a genuinely hard problem.
Most organizations try to solve this with an EMPI. But an EMPI only handles patient identity, not encounters or observations. It connects to a limited set of systems, usually via FHIR or IHE, and uses a narrow set of matching techniques. But the warehouse sees more data from more sources than the EMPI ever will. Why not do the record linkage there?
Warehouse-native MDM tools like Splink do exactly this. Probabilistic and ML-based matching at scale across the full dataset. It runs on Spark and DuckDB, handles millions of records, and is fully open source.
Terminology matters just as much. The silver layer models need strict vocabulary constraints. When someone queries the problem/diagnosis model, there should be a single fine-grained ontology encoding it, like SNOMED CT. Not ten different terminologies mixed together. OHDSI’s OMOP Vocabulary has done significant work harmonizing healthcare terminologies for PostgreSQL. The same approach needs to be brought into the warehouse to constrain and validate the silver layer.
All of this is possible today. But none of it works without a concrete specification.
There’s prior art here, but nothing that does the whole job.
OHDSI’s OMOP CDM has contributed significantly to terminology and vocabulary harmonization. It also provides clinical data models as SQL table definitions. But we don’t need CREATE TABLE statements. The silver models are constructed as views on existing tables in the warehouse. We need materialization specs: what the output should look like, what terminology constraints apply, and how to validate it.
The Tuva Project is closer to what’s needed. It ships warehouse-native clinical models with built-in tests, terminology constraints, and dbt packages. But like OMOP, Tuva doesn’t try to model maximal clinical concepts. Both capture a small subset of the information an enterprise actually generates.
openEHR archetypes are the only effort I’m aware of that attempts to model the full breadth of clinical data. What we need is something like Tuva, but maximal. Built on openEHR archetypes.
Concretely, that means a set of tests that run on the warehouse and encode the archetype constraints as SQL assertions. Does this field use this SNOMED CT value set? Are there duplicate patient records? Does this table match the archetype’s expected shape? Anyone should be able to point the test suite at their warehouse tables, and passing tests mean the archetype model has been implemented correctly. This is just SQL. Tools like dbt tests and SQLMesh audits already provide frameworks for exactly this kind of validation. It’s not hard to derive from openEHR’s archetype definitions.
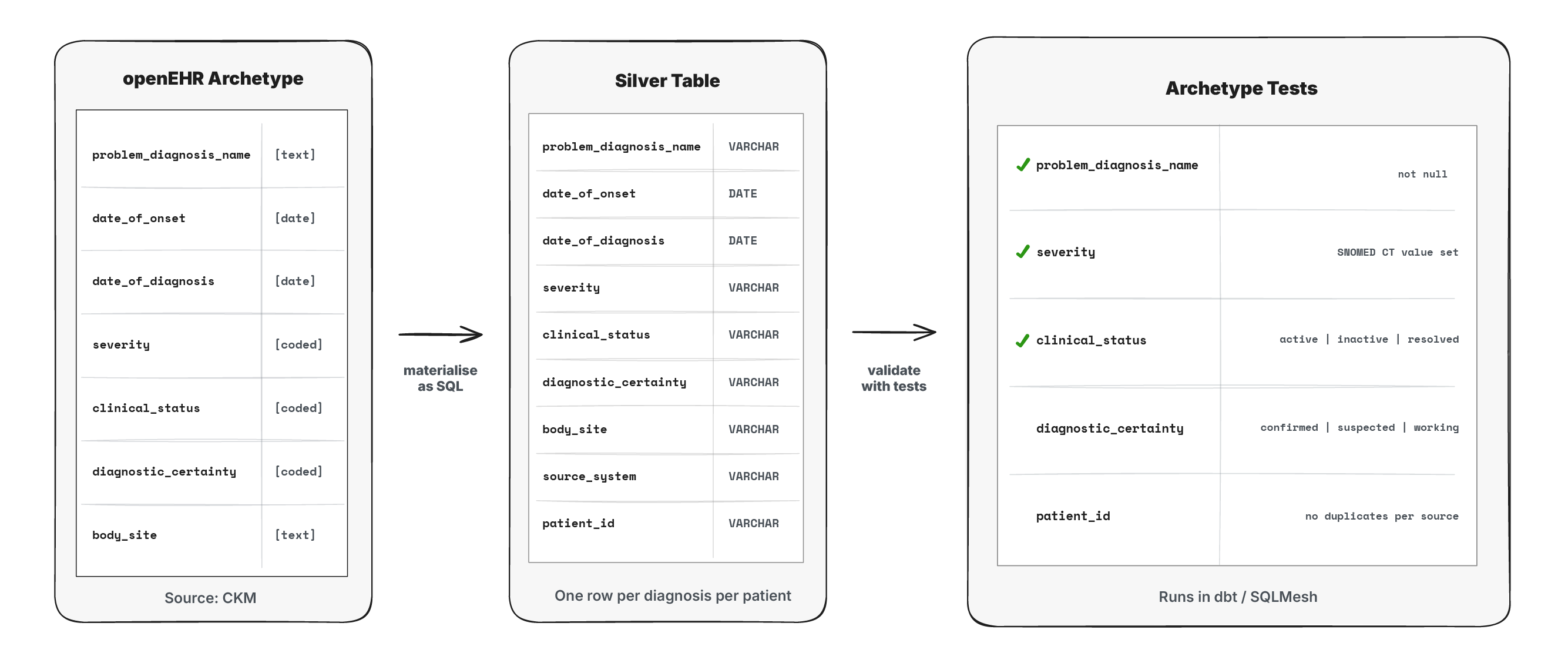
What is harder is getting the archetypes themselves constrained tightly enough. Current openEHR archetypes are intentionally loose to support many use cases. For the silver layer, they need to be stricter: fixed terminology bindings, mandatory fields, no ambiguity. This constraining could happen at the organizational level, but that causes the same problem as FHIR profile proliferation. You end up with fifty versions of the same archetype and different vendors supporting different variants. It needs to happen at the international level.
These are my thoughts from working with and hearing from different organizations and governments trying to solve this problem. There’s still a lot to figure out, but it is a direction I think is worth pursuing. If you’re working on something in the same space, I’d love to hear from you. Drop a comment below, or book a call and let’s talk.
I make the case that SQL could be the solution to simplifying the layers of complexity in health data architecture. This is a written version of my talk at EHRCON 25.

While open standards set the rules, open source gets the work done. Discuss choosing tools, handling semantics and making health systems interoperable.

Health IT has various standards, and choosing the right one is often confusing. Understand the differences clearly to select the right standard.
No comments yet. Be the first to comment!
