
OpenEMR: The Complete Guide to the World’s Most Popular Open-Source EHR
A practical guide to the world's most popular open-source EHR, its architecture, FHIR APIs, Docker setup, and where it can fit well.
November 12, 2025
Ever wonder how a simple blood pressure reading becomes part of a standardized data model? Discover the classes of openEHR archetypes and the lifecycle that shapes them.
The ever-expanding knowledge base in the healthcare industry poses unique challenges for data modelling. A conventional information system struggles to keep up with the increasing complexity of medical information and its relationships. openEHR’s two-level information model design is an important solution in this regard, separating the data model into an information model and a knowledge model. A key element of this are Archetypes and Templates.
An Archetype structures clinical data making it reusable and vendor neutral. Each archetype represents a single, discrete topic or theme e.g. blood pressure, medication order. Archetypes once published can be reused to create Templates that are customizable to your specific use case. There are 3 main categories or classes of archetypes, as defined in the openEHR Reference model. Each has specific attributes supporting the recording and reuse of clinical information.
The main archetype classes in openEHR are COMPOSITION , SECTION , and ENTRY. The image below shows how these classes are organized.
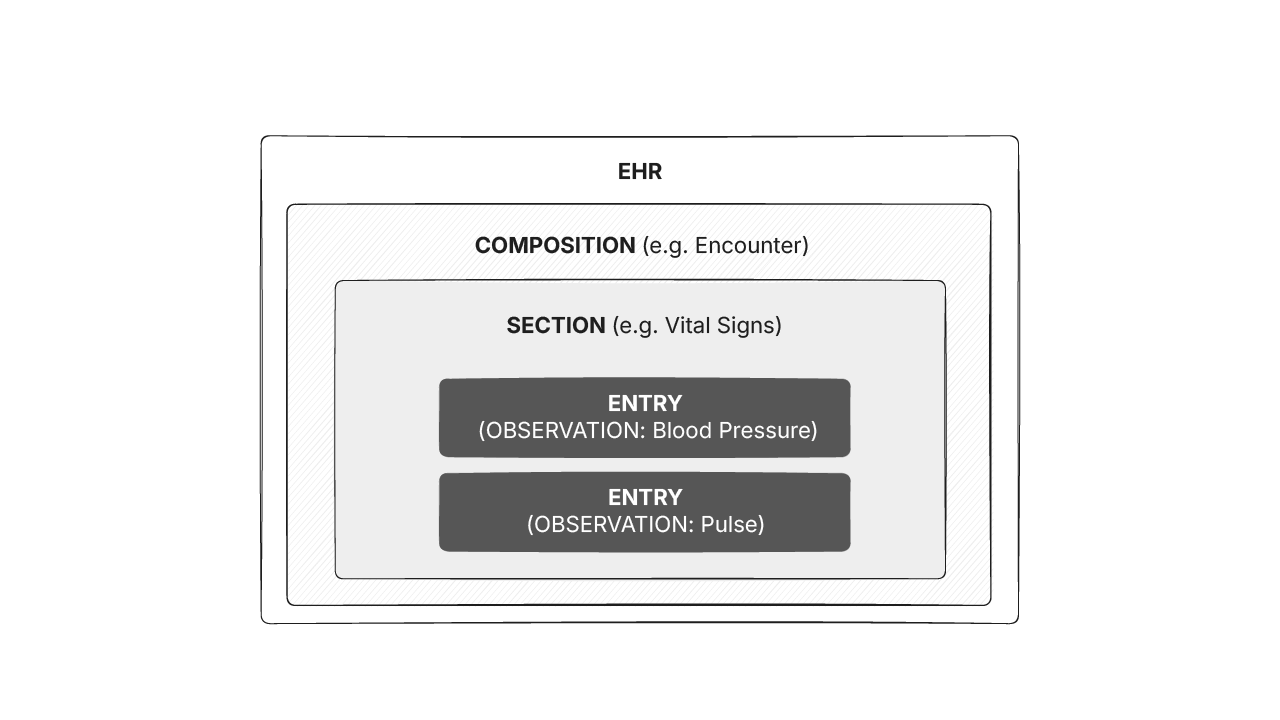
An openEHR Composition corresponds to commonly used clinical documents or events such as a Discharge summary, Operative notes, or a Prescription. It is a container class and is the unit of modification, attestation and committal to the EHR. Compositions can be considered equivalent to the traditional paper record, or as a blank piece of paper in the paper record that conveys some high level contextual information into which detailed clinical information will be added.
openEHR Compositions contain Sections which are organising classes that provide a framework within which clinical information can be placed. They usually do not carry any semantic meaning and can be considered equivalent to headings found on a traditional paper record.
Some examples of sections are History, Physical examination and SOAP(E) organization of the EHR.
Entries hold the main clinical content and are standalone semantic units of information. It allows information to be grouped together and reused in different settings. They can also be interpreted independently of the composition or section within which they are locatedBlood pressure, Pulse, Diagnosis etc. are examples of entries. Entry is also an abstract type and has concrete subtypes defined as follows.
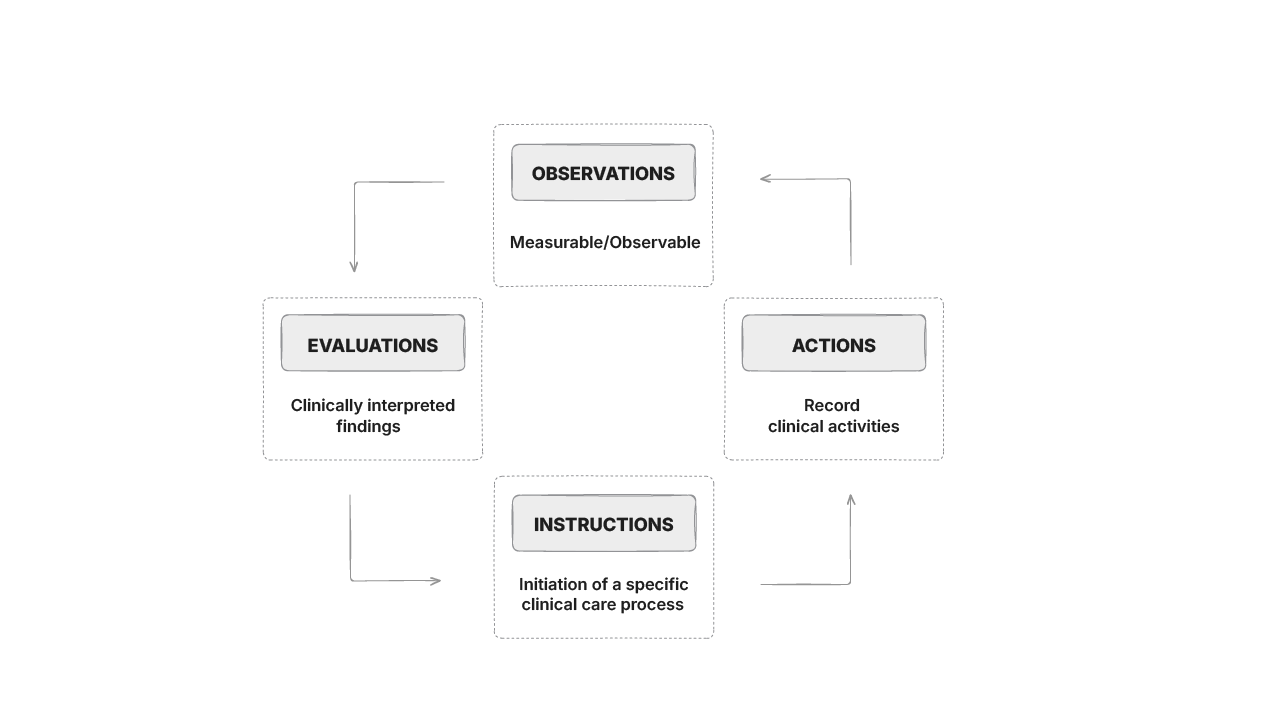
These are uninterpreted clinical observations or evidence which includes anything reported by the patient as a symptom, event or concern, measurements or test results and findings of examinations. Observations are used to represent data that is observable and measurable, can be collected repeatedly or over a period of time, and an interval measurement makes sense. Blood pressure, ECG, weight, height etc are examples of observations
These are used to capture clinically interpreted findings, opinions and summary statements. Evaluations are meta-information to observations, based on ideas that occur to the clinician on the basis of interpreting observations. It is usually not required to have a time series or interval measurement of such data. Risk assessments, Problem/diagnosis, goals, adverse reactions etc. are some examples of Evaluations
These are statements about what should happen in the future and usually go hand-in-hand with Actions. Clinical orders for care, initiation of a medication order workflow etc. are examples of Instructions.
Actions are statements about clinical activities that were executed. Often, Instructions and Actions are complementary and the Action represents the ensuing state of the Instruction such as ‘scheduled’ or ‘completed’. It is, however, not always necessary to have an instruction before an action, or an action to follow an instruction.
These are reusable archetypes that can be used within any Entry or any other Cluster and are particularly useful when recursiveness is important. They often represent common domain patterns required in many clinical scenarios such as size, symptom, inspection and relative location. They are useful for capturing the first principles of clinical examination and history.
For example, a Medical History OBSERVATION can contain a Symptom CLUSTER (e.g. to capture a presenting complaint of Headache). This Symptom CLUSTER can then contain further Symptom CLUSTERS to capture secondary symptoms (e.g. photophobia or vomiting).
Existing archetypes can be refined so as to meet specific clinical requirements, e.g. specialising the ‘weight’ archetype to create ‘birth weight’. The specialised archetype inherits all features of the pre-existing archetype and can have additional new elements or narrower constraints. A query based on the parent archetype can return data based on the specialised archetype but not vice versa. You can now search for archetypes at the appropriate levels for your use case.
Not all artefacts (archetypes, templates, termsets and release sets) in the Clinical Knowledge Manager (CKM) are ready for use. Various states and icons are used in the CKM to differentiate between stable and unstable artefacts. These icons are displayed alongside the artefact name in the left-hand menu indicating the publication status of the clinical content. The below image represents the icons, status and description.
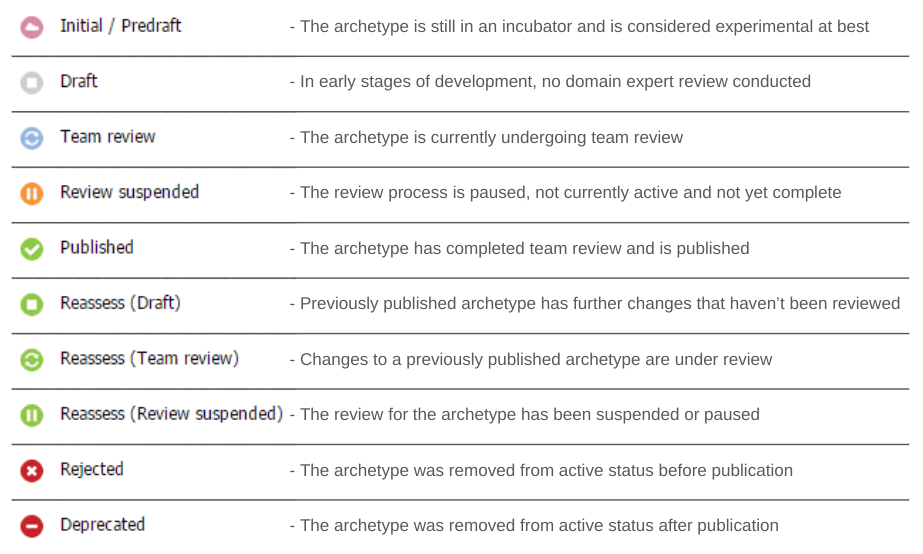
The below image represents the lifecycle of an artefact and how it moves between the different stages in the form of a state machine.
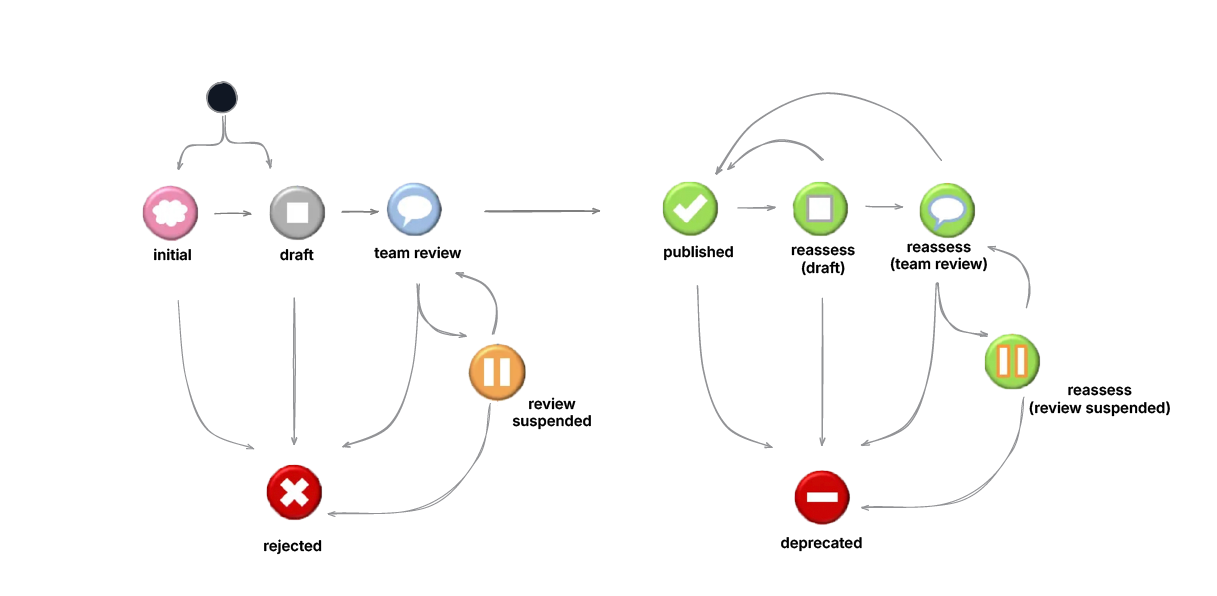
The first stage of an artefact in the CKM is ‘Initial/Predraft’. From here it moves to ‘Draft’ and then ‘Team Review’. An artefact in any of these three stages can move to ‘Rejected’. From ‘Team Review’, an artefact can go to ‘Review Suspended’ and then be ‘Rejected’.
If the artefact passes the ‘Team Review’ it is ‘Published’ which is considered a stable status. In case of any changes to this artefact due to a new clinical requirement or otherwise, it can be moved to ‘Reassess(draft)’ or ‘Reasses(team review) from where it can be ‘Published’. A review can be suspended, i.e. the artefact can move to the ‘Reassess(review suspended)’ stage from ‘Reasses(team review)’. From all of these states, an artefact can be ‘Deprecated’.
It is also important to note the constraints placed on artefact status based on this state diagram, i.e. a resource can only be ‘deprecated’ once it has already been ‘published’. If the resource has never been ‘published’, it is ‘rejected’. Additional states such as ‘translation’ and ‘terminology’ are used to reflect resources being translated to different languages and terminology bindings respectively.
Having a deeper understanding of openEHR archetype classes and the publishing lifecycle can help you develop applications that better suit your specific clinical needs. An archetype is structured with a Composition container, organized with Sections, and clinical information is populated by Entries. Clinical information is further classified into Observations or measurable data, Evaluations or physician interpretations, Instructions for clinical workflows and Actions taken. Recursive information about clinical events can be recorded using Cluster classes.
During the process of artefact creation (this could be archetypes, templates or termsets), a resource goes through various stages. These need to be accurately represented and understood in order to ensure the correctness and completeness of reusable clinical components. With 10 detailed stages such as Draft, Published, Rejected and Deprecated provide information on the artefact lifecycle and the validity of the information it contains.
Get started with your openEHR learning with our free openEHR Fundamentals Course. Register today!
A practical guide to the world's most popular open-source EHR, its architecture, FHIR APIs, Docker setup, and where it can fit well.

This project breakdown looks at how we built Tip2Toe, a rare disease phenotyping application for Karolinska University Hospital.
Why openEHR works better as a silver layer in your data warehouse than as a CDR, and what that means for clinical data at scale.
No comments yet. Be the first to comment!
