
OpenEMR: The Complete Guide to the World’s Most Popular Open-Source EHR
A practical guide to the world's most popular open-source EHR, its architecture, FHIR APIs, Docker setup, and where it can fit well.
January 13, 2026
If you have come here thinking openEHR is some piece of software you can download or a product you can buy, you are wrong. It’s an open standard in health IT that defines how health data should be structured, stored, and exchanged to remain meaningful over time, across systems, and between organizations.
The roots of openEHR trace back to the early 1990s with the GEHR (Good European Health Record) project, led by Professor David Ingram at University College London, which aimed to create a European-wide electronic health record architecture.
This evolved into the openEHR Foundation, established in 2003 by Dr. Sam Heard and Thomas Beale. They brought together researchers, clinicians, and informaticians who shared a vision: health data should outlive the software that creates it. Together with a growing international community, they built a framework designed to last generations. The foundation operates as a non-profit, vendor-neutral organization, developing and maintaining specifications that anyone can implement.
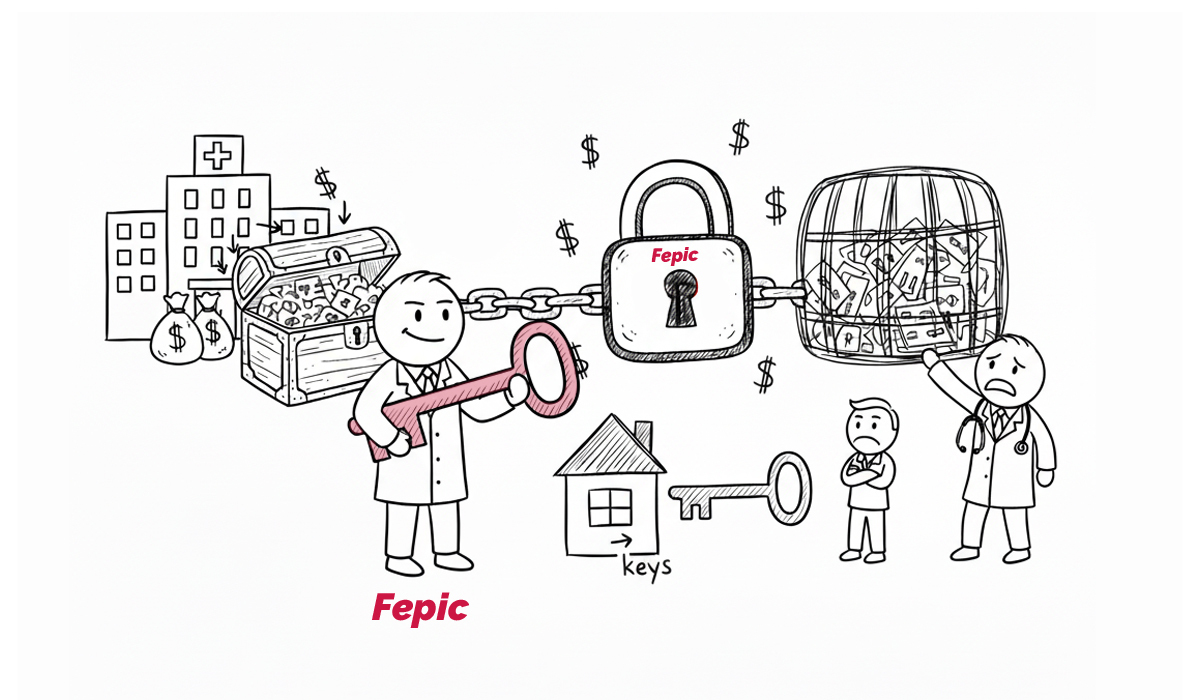
Picture this scenario: A hospital invests millions in an Electronic Health Record (EHR) system. Clinicians spend years documenting patient encounters, building up a treasure trove of clinical data. Then one day, the vendor, let’s call them “Fepic” (wink wink), decides that sharing your own data will cost extra. Want to integrate with another system? That’ll be another seven figures, please. Need to migrate away? Good luck extracting anything meaningful without their proprietary tools. It’s the healthcare equivalent of buying a house but renting the keys from the builder. Forever.
In most traditional systems, the clinical knowledge of what healthcare data means and how it’s structured is hardcoded directly into the application or stuck with the vendor. When the software changes or goes away, the semantic meaning of the data often goes with it. This is the vendor lock-in problem.
openEHR’s core innovation solves this through separation of responsibilities:
This separation means the clinical meaning of your data doesn’t depend on any particular application. Your “blood pressure” data has the same structure and meaning whether it was captured in a mobile app in Mumbai, a hospital system in Munich, or a research database in New York.
So how is the data even modelled? openEHR takes an approach called maximal modelling. Rather than creating a minimal data structure that covers only immediate needs, archetypes are designed to capture the full range of possible data points for a clinical concept.
For example, a blood pressure archetype doesn’t just capture systolic and diastolic values, it can also accommodate body position, cuff size, measurement location, device information, and clinical interpretation. Most applications won’t use all these fields, but they’re available when needed.
This is why we can say, openEHR allows for the data stored once and can be interpreted and reused decades later. Since the clinical models are built and governed by a global community, they evolve with medical knowledge while keeping past records valid. This makes openEHR ideal for long-term patient care and unified data platforms.
Want to dive deeper into the problems openEHR solves? Check out our Why openEHR? article for a comprehensive look at how healthcare evolved from custom-built systems to vendor-controlled monoliths, and why openEHR offers a better path forward.
For now, let’s continue to explore how openEHR achieves this through its elegant multi-level architecture of Reference Models, Archetypes, and Templates. These clinical models are collaboratively developed and publicly available in the Clinical Knowledge Manager (CKM).
openEHR employs what’s called multi-level modelling—a layered approach that separates stable technical foundations from evolving clinical content.
The Reference Model is the technical foundation and serves as the “rules” of how to store the healthcare data in openEHR. It defines the fundamental building blocks:
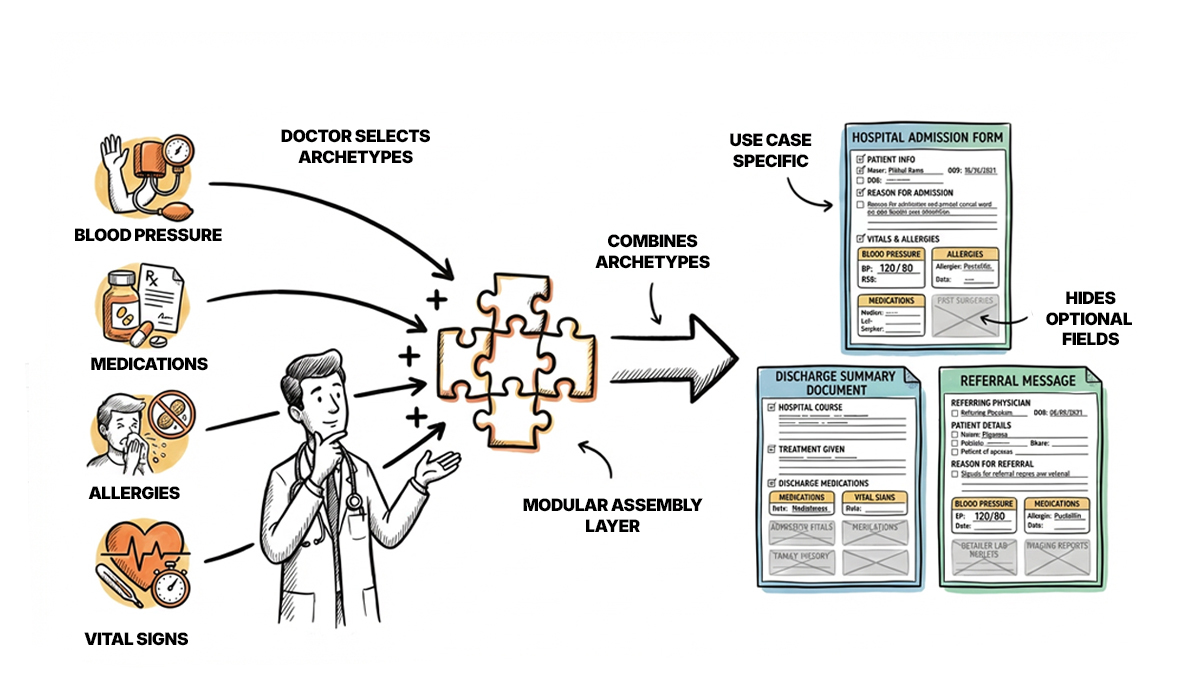
Archetypes define the clinical semantics—what the data means. Each archetype represents a single, reusable clinical concept: a blood pressure measurement, an allergy record, a medication order.
Crucially, archetypes are developed by domain experts such as clinicians and informaticians and not by software developers. They’re expressed in a formal language (Archetype Definition Language, or ADL) that’s independent of any programming language or database technology.
Templates combine archetypes for specific use cases defining which archetypes to include, which optional fields to display, and how they assemble into practical forms, documents. Templates act as the bridge between reusable archetype definitions and the actual data structures used in clinical workflows, enabling context-specific customization while maintaining semantic consistency.
Want to Implement openEHR? Understanding the “what” and “why” is the first step. If you’re ready to explore implementation on how to set up an openEHR system, model clinical data, and build applications — check out our Setup openEHR server in under 15 mins.
Because openEHR is an open standard, the answer is pretty simple: anyone.
openEHR is designed to support long-term, clinically meaningful health data while actively preventing vendor lock-in. Interoperability is inherent to its approach: when systems use shared archetypes, data can move seamlessly between platforms without complex mappings or loss of meaning.
Since the data model is independent of any single application or vendor, organizations can switch systems, adopt new tools, or build custom solutions while keeping their data intact and usable. This separation of data from software also makes openEHR future-proof, acknowledging that clinical systems may change every 7–12 years, while patient health records must remain valid for a lifetime.
Clinical credibility is preserved through clinician-led archetype development, ensuring that data structures reflect real-world practice rather than technical assumptions. In addition, openEHR aligns with regulatory requirements for interoperability and data portability, such as GDPR, and enables secondary uses of health data—including research, quality improvement, population health analysis, and AI.
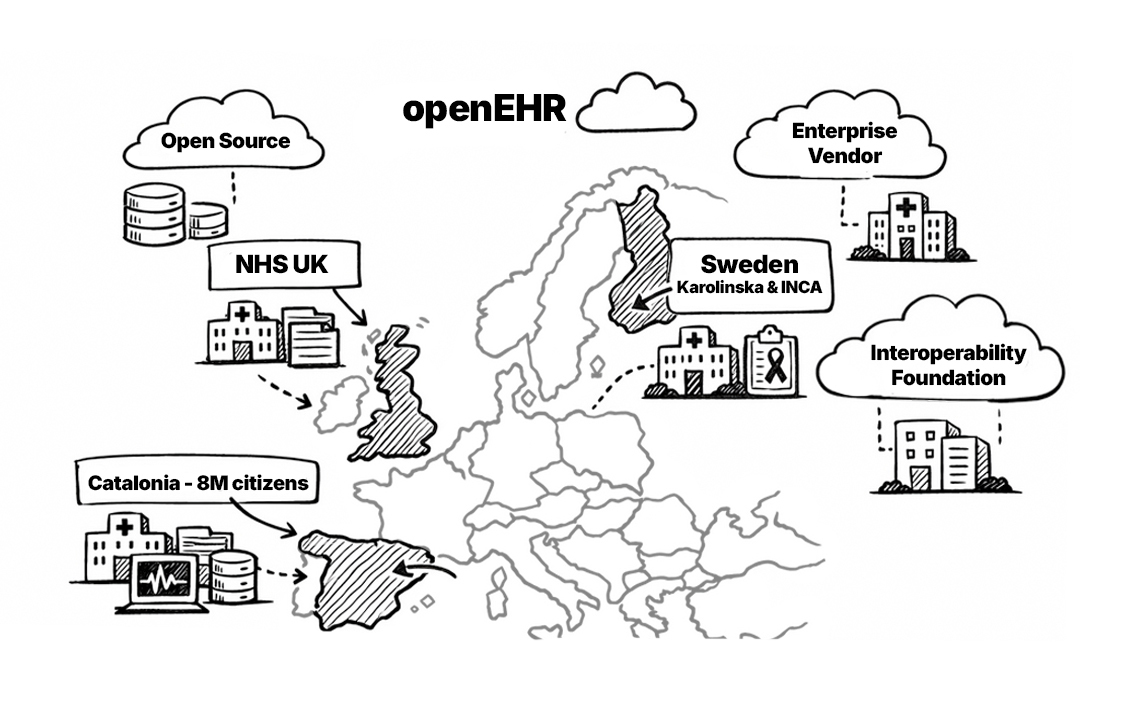
openEHR has gained significant traction, particularly in certain regions of Europe. The United Kingdom NHS adopted openEH for shared care platforms across multiple regions. In Catalonia, we implemented large-scale, open-source openEHR-powered EHR for 8+ million residents. More about it in Catalonia’s openEHR CDR for 8 million people. Meanwhile in Sweden, multiple regions including Karolinska University Hospital; Swedish Cancer Registry (INCA) have adopted openEHR.
Major vendors like Better, Ocean Health Systems, EHRbase (open source), and Code24 provide openEHR platforms. Additionally, organizations like the Apperta Foundation promote openEHR adoption through open-source initiatives.
This is perhaps the most common question, and it deserves its own detailed treatment. Here’s the short version:
FHIR and openEHR address different challenges in healthcare IT: FHIR excels at real-time data exchange through its API-driven, resource-based architecture, while openEHR is purpose-built for long-term clinical data management using flexible archetypes and templates.
FHIR’s fixed resource definitions (Patient, Observation, etc.) require extensions for new clinical requirements, increasing development effort, whereas openEHR allows healthcare organizations to add new data fields without disrupting existing systems.
While FHIR dominates in interoperability scenarios, openEHR outperforms when structured, versionable clinical data must remain adaptable over decades, making them complementary standards rather than competing alternatives.
Are you interested in building healthcare technology that leverages vendor-neutral healthcare standards with openEHR? Take a look at our openEHR Fundamentals to get started.
A practical guide to the world's most popular open-source EHR, its architecture, FHIR APIs, Docker setup, and where it can fit well.

This project breakdown looks at how we built Tip2Toe, a rare disease phenotyping application for Karolinska University Hospital.
Why openEHR works better as a silver layer in your data warehouse than as a CDR, and what that means for clinical data at scale.
No comments yet. Be the first to comment!
