What are FHIR Resources? Explained
FHIR resources are the building blocks of healthcare data exchange. Everything in the FHIR world, from a patient record to a lab result or a prescription, is modeled as a resource.
In this lesson, we’ll walk through the official FHIR specification, break down what a resource looks like, and explain key concepts like data types and cardinality. By the end, you’ll know how to read a FHIR resource page and how to validate whether your resource is correct.
Exploring the FHIR specification
When you open the FHIR specification Resource Index, you will see a long list of resources.
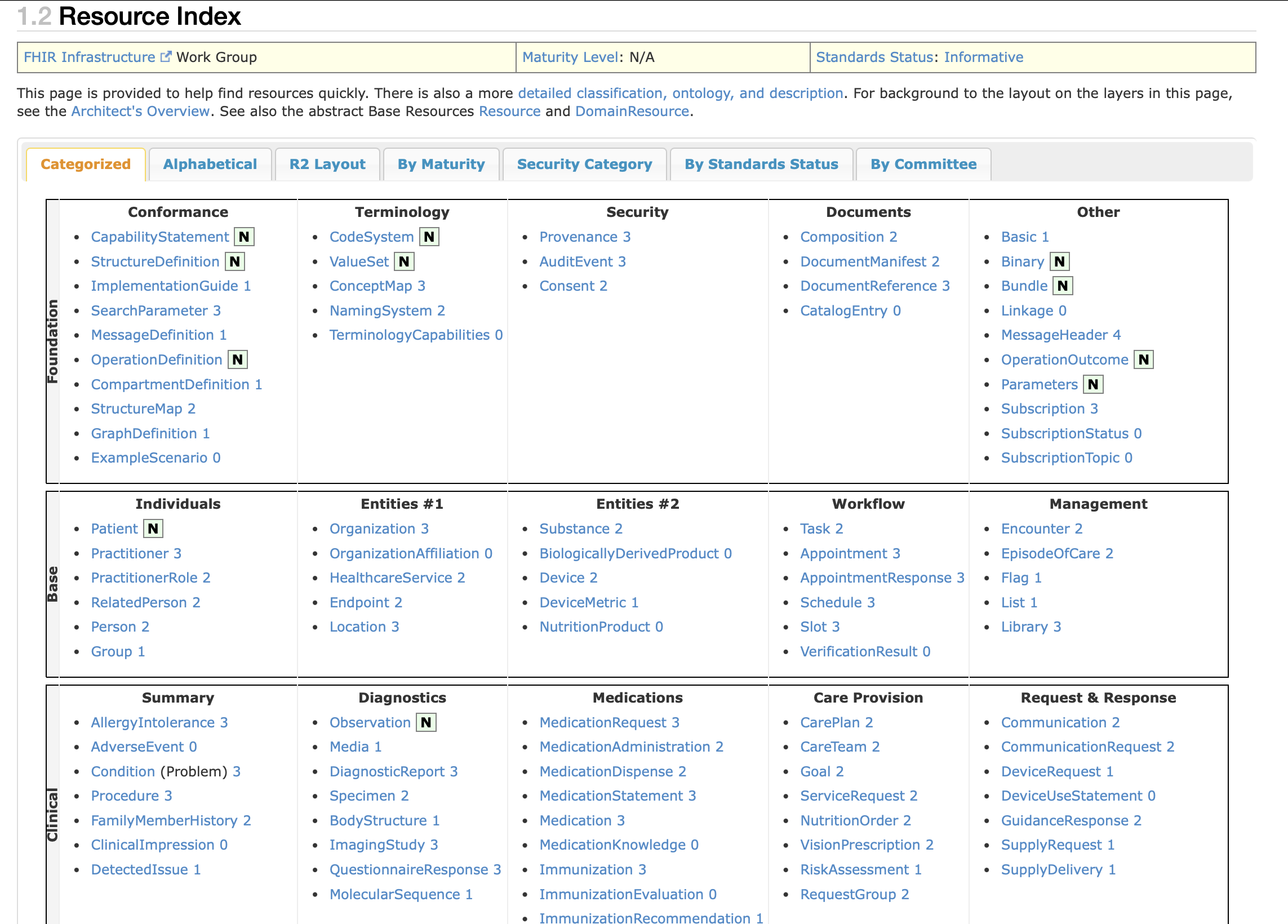
These resources can be sorted by various parameters for convenience, including alphabetically, by category and more.
For this lesson, sort it By Maturity. The numbered levels(1-5) have the following meaning:
- Level 5: very stable, unlikely to change
- Level 0: experimental, may change anytime
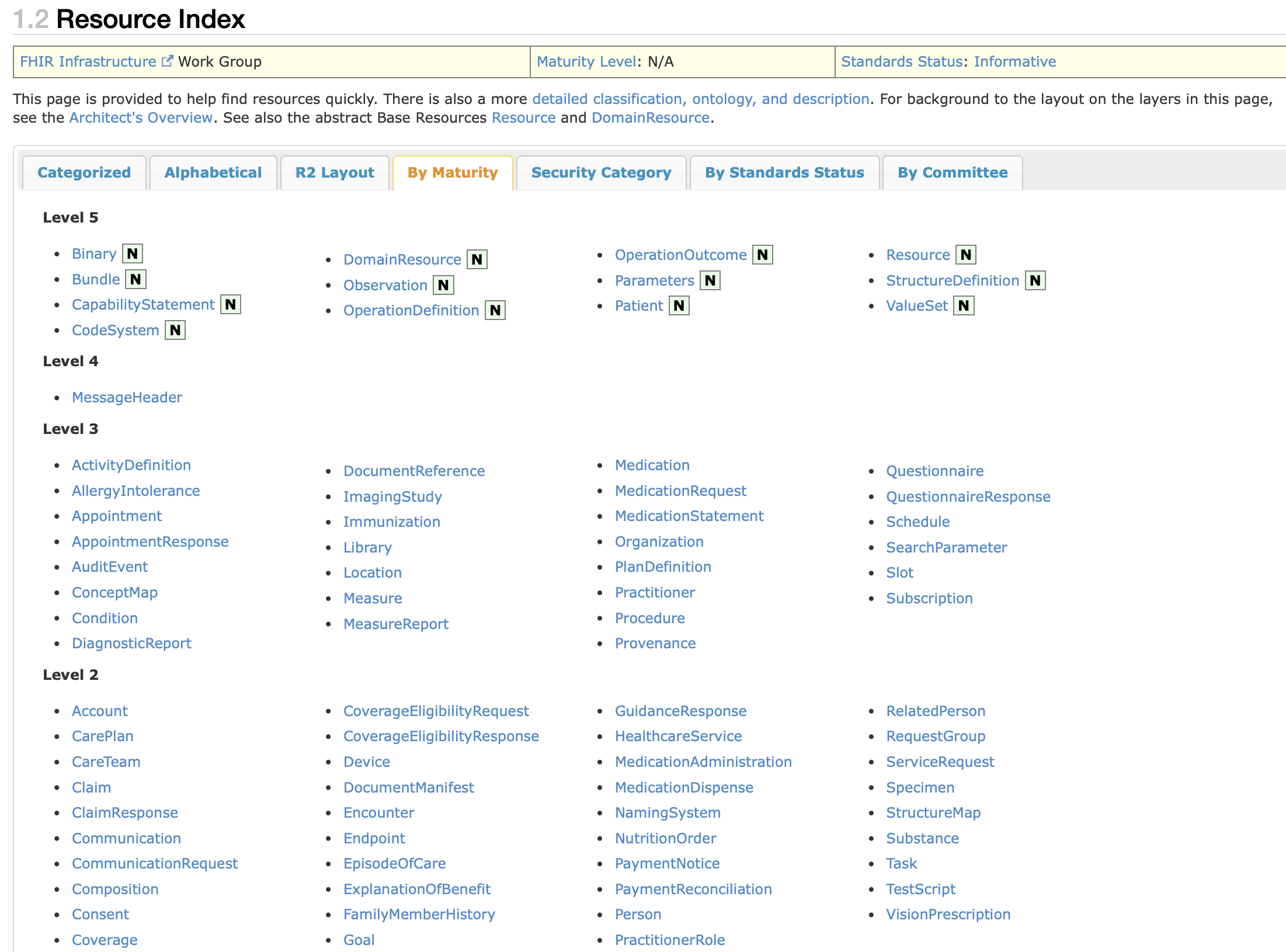
You will also notice that some resources are marked N for Normative. This indicates that they are part of the official, stable standard and will not change in a way that breaks compatibility in future releases. This provides confidence to developers and vendors that they can safely build production systems on them.
As an example, let us take a look at the Patient resource.
Understanding the Patient resource
The Patient resource contains demographic and other administrative information about the individual or animal receiving care.
These are some of the sections you will find in the Patient resource specification,
- Scope and Usage: Defines who or what the resource represents
- References: Lists other FHIR resources that reference the current resource
- Resource Content: Depicts the structure of the resource in multiple formats including a tree structure, UML, XML and JSON
To understand and read the Patient resource we need to refer to the Resource Content section. When the tree view is selected (tab name: Structure), you can see a tabular representation of the fields the resource contains, cardinality, data type and description.
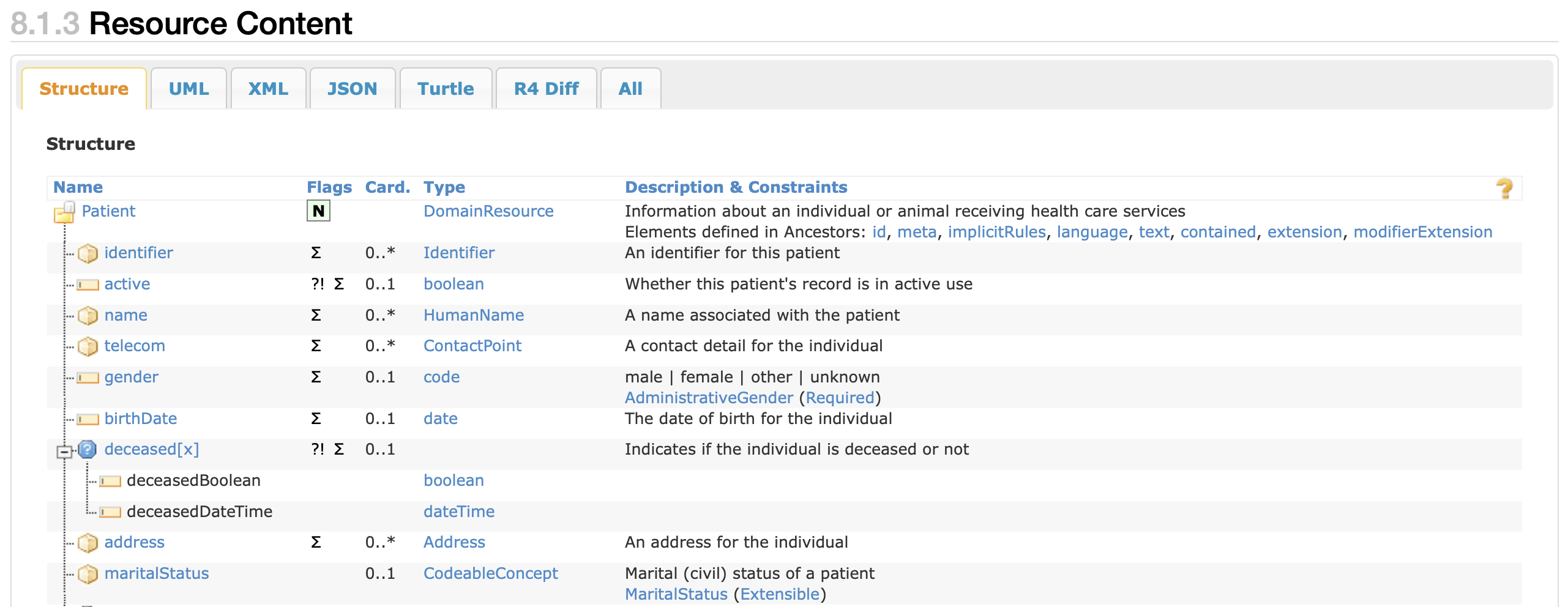
Some fields included in the Patient resource are,
identifier: Contains business identifiers like medical record numbers.active: Contains a boolean value representing whether the record is in active use.name: Contains the name of the patient.telecom: Contains telecommunication details of the patient such as email ID or phone number.
To understand each field better, you can click the name of the field, for example on clicking identifier you are redirected to its documentation.

patient.identifierCardinality
The cardinality of a data element represents the minimum and maximum number of times a data element can appear in a resource. For example,
0..*: The element is optional and can repeat multiple types (array).0..1: The element is optional but only one value is allowed.1..1: The element is mandatory and only one value is allowed.
Data types
FHIR has two broad categories of data types,
- Primitive types: Including simple values like
boolean,stringanddate. E.g. The fieldactiveis of typeboolean - Complex types: Includes nested structures with multiple fields. E.g.
HumanNameincludesfamily,given,prefix,suffix

JSON and XML representations
The Resource Content section also has tabs to view JSON and XML representations of the Patient resource.
As an example, here is a simple Patient resource in JSON:
{
"resourceType": "Patient",
"active": true,
"name": [
{
"use": "official",
"family": "Smith",
"given": ["John"]
}
]
}and here is the same patient in XML:
<Patient xmlns="http://hl7.org/fhir">
<active value="true"/>
<name>
<use value="official"/>
<family value="Smith"/>
<given value="John"/>
</name>
</Patient>When looking at both formats you will notice that,
- In JSON you explicitly declare
"resourceType": "Patient", whereas in XML the resource type is implied by the root element<Patient> - XML uses
value="..."attributes for data types likeboolean,stringanddate
In the FHIR specification, what does a cardinality of '1..1' mean for a field in a resource?
Validating resources
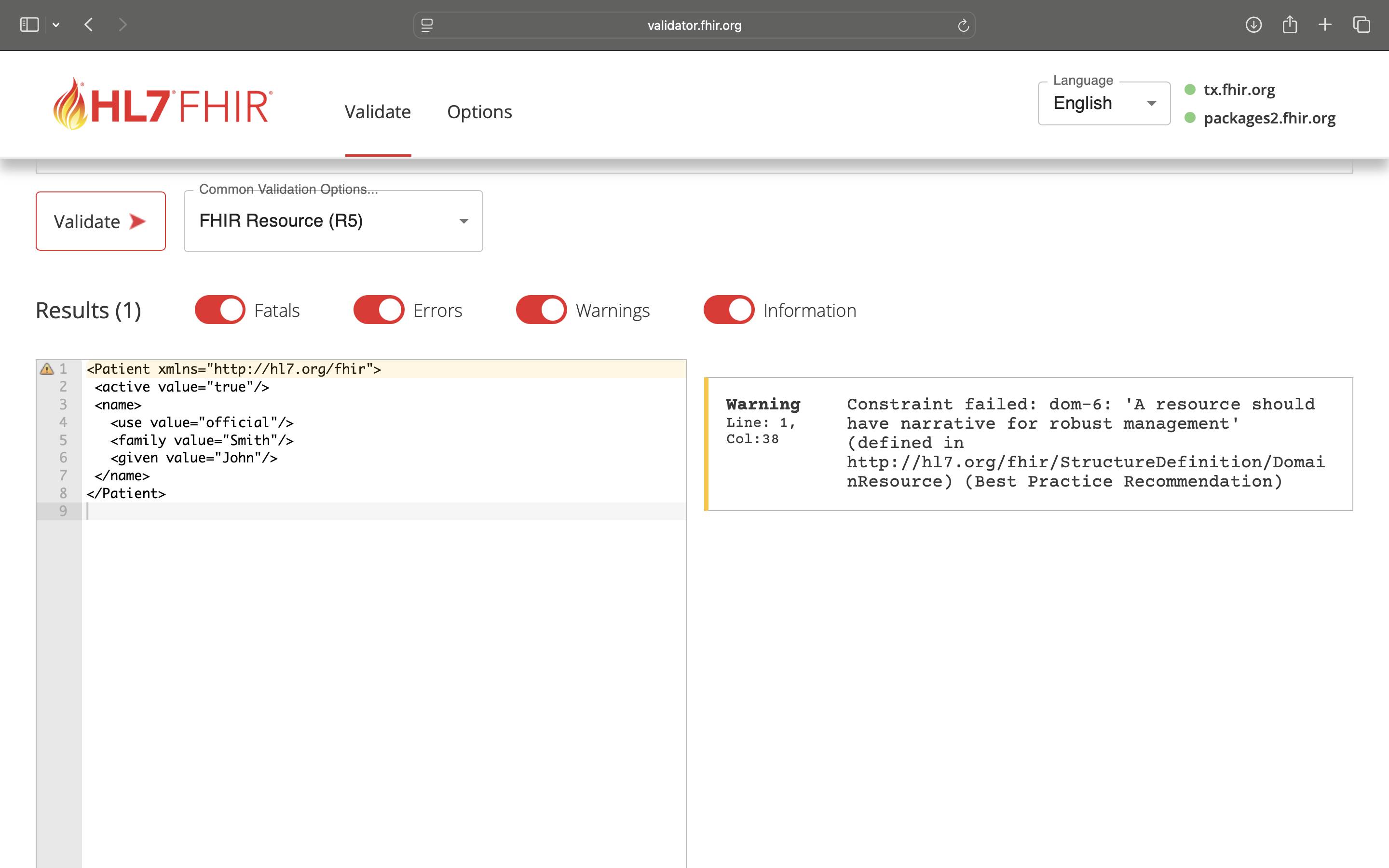
Creating a FHIR resource is only the first step, it is essential to make sure that it is valid. Validation ensures that the resource follows the FHIR specification and enables consistency, accuracy, and hence, interoperability of data.
Without validation, different systems may reject your resource or misinterpret data, leading to broken workflows and interoperability gaps.
FHIR Validation typically checks the following:
- Structure of the resource and if it follows the correct JSON schema.
- Cardinality of data elements, ensuring mandatory elements are present and optional ones are used correctly.
- Terminology usage, checking if coded fields are using the right value sets.
- Profile/IG adherence, ensuring the resource conforms to a specific profile and satisfies the prescribed constraints.
Two commonly used online FHIR validation tools are,
- Official HL7 FHIR validator: A Java based service that checks resources against base spec and IGs
- Inferno Resource validator: A web-based validator from ONC’s Inferno project used for US Core and certification testing
Most programming languages have FHIR libraries with built-in validation.
Which of the following is an example of a complex data type in FHIR?
Summary
A FHIR resource is a structured representation of healthcare data. Each FHIR resource has fields with clear data types and cardinality rules. There are broadly two types of data elements in FHIR, primitive and complex. JSON and XML representations of FHIR resources follow the same structure; they are simply encoded differently in terms of syntax. FHIR validators are a helpful tool when working with FHIR, as they ensure that resources follow the specification.
Once you understand how to read the resource tree, data types and cardinality, it becomes easy to confidently model anything in healthcare with FHIR.
